 TechnologyAIと様々な先端技術を用いて、お客さまの課題に対応いたします。
TechnologyAIと様々な先端技術を用いて、お客さまの課題に対応いたします。
音声
音声分野では、長い研究の歴史のある音声認識から、音の識別、非可聴音にまでAIが適用されています。なんらかの音を識別・認識しようとした場合、たいていは認識対象以外の何らかの雑音が含まれています。近年大きく発展した深層学習を用いると雑音が含まれるような音に対してロバストな成果を上げるケースもあります。しかし、個々の環境において深層学習が有効でない場合もあり、そのようなケースでは音源の機構、雑音の性質、集音器の特性をとらえたアプローチが有効になってきます。古典的な音声解析手法から最新の深層学習を用いた方法を用いてさまざまな音に関わる課題の解決をサポートしています。
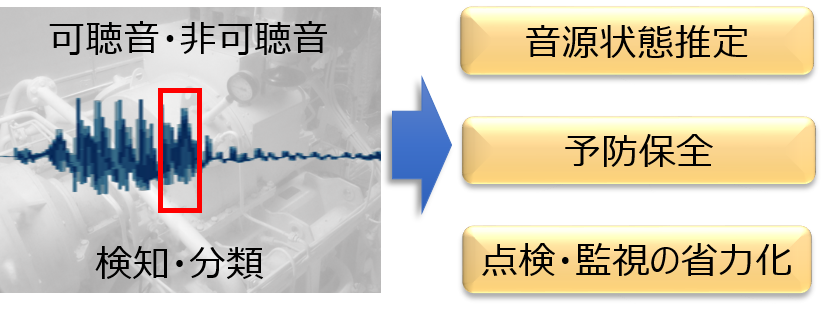
音の検出・音識別
音声に限らない特定の種類の音の検出や、正常な状態および異常な状態の音を聞き分け、音から活用できる情報を引き出す技術です。
これまで、機械が発する異常音の検知による予知保全や故障検知は、人間の耳に頼っていました。
AIの活用は、これを補完・代替するだけでなく、人間の耳では聞き取れない周波数帯の音の検出や識別をすることも可能とするためさらに高度化が期待できます。
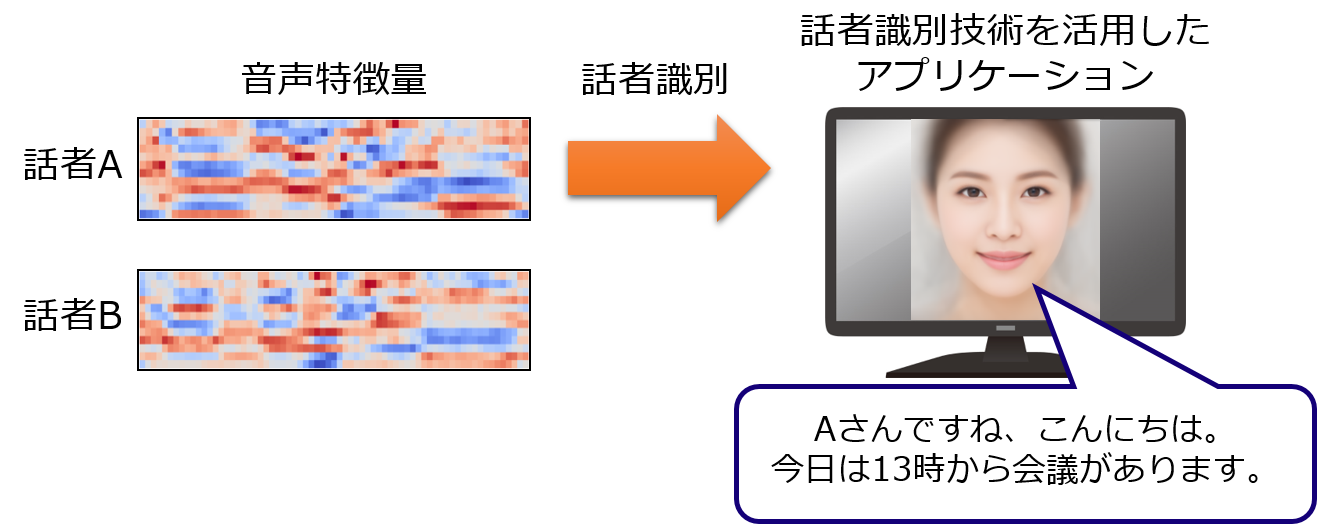
話者識別
話者識別は、人の声から話者を識別する技術で、話者ごとに対応を変えるアプリケーションや会話における発言者の特定に活用することができます。
当社では、古典的な音声特徴量であるMFCCだけでなく、深層学習を活用することで高い識別精度を実現しています。
また、人の声は時間とともに徐々に変化していきます。当社では、変化していく声の特徴量を自動的に学習することで永続的に話者識別精度を保つことが可能となります。
まずはお気軽にお問い合わせください!