
概要
グラフニューラルネットワークやグラフアルゴリズムなどの最先端の知見をもとに、グラフ構造を含むデータの利活用・研究開発におけるお客さまの課題解決を支援いたします。
グラフ構造とは
グラフ構造とは、データ間の関係性やつながりを表現する構造です。点(ノード)と点同士を結ぶ辺(エッジ)によって表現されます。この構造を利用することで、データがどのようにつながり、影響を与えているのかを把握することが可能になります。グラフ構造を含む身近な例としては、図1に示すような、ソーシャルネットワークや道路交通網、化合物などがあります。
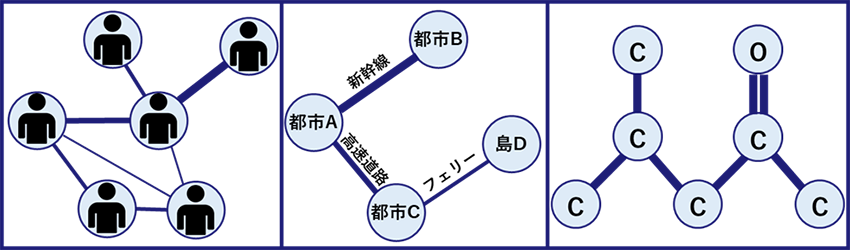
図1 身近なグラフ構造を含むデータ
(左から順に、ソーシャルネットワーク・道路交通網・化合物の構造を図示)
グラフ構造を活用することで、従来のデータ解析では困難だったデータ間の複雑な関係性を解明し、新しい洞察を得ることができるようになります。近年では、グラフ構造を対象とした深層学習であるグラフニューラルネットワーク(Graph Neural Network, GNN)が急速に発展し、化合物の特性予測や原子配置の時間変化予測*1、ニュースの推薦システムなどにおける実用化に向け、研究開発が進められています。また、Google Maps®における到達時刻予測(ETAs)機能*2といった実問題への応用も進んでいます。
サービス内容
グラフ構造を含むデータの利活用・研究開発に関する課題をお持ちのお客さまに対し、当社の持つグラフニューラルネットワークやグラフアルゴリズムなどの最先端の知見に基づき、課題のヒアリングを行った上で、最適なソリューションを提案いたします。
サービスメニュー
左右スクロールで表全体を閲覧できます
|
上記のサービスを組み合わせた、最適なソリューションの提供イメージは以下のとおりです。
データを利活用したアイデア具現化や効果検証をご希望のお客さま向け
お客さまが抱えている具体的な課題についてヒアリングさせていただいた上で、最適な技術・手法を提案し、アイデア具現化や効果検証までの一貫したサービスを提供いたします。
【イメージ】
|
グラフ構造を含むデータに関して、既に研究開発をされているお客さま向け
お客さまの研究内容やフェーズについてヒアリングさせていただいた上で、柔軟かつきめ細やかなサービスを提供し、お客さまの研究開発を加速させます。
【イメージ】
|
適用例
左右スクロールで表全体を閲覧できます
|
|
文章の意味的類似度の推測
GNNの自然言語処理への応用の一例として、二つの文章の意味の類似度を推測するタスク(Semantic Textual Similarity, STS)へ適用した事例を紹介します。
本タスクでは、二つの文章が意味的にどれほど類似しているかを推定します。これは、単なる単語の類似性(例:「ボール」と「球」)だけでなく、文全体の意味的な一致度(例:「私はサッカーが好きだ。」と「私達は球技が嫌いではない。」の類似度)を捉えることを目指します。特に複雑な文章では、形容詞による名詞の修飾や、接続詞による文章間の論理関係など、単語や句同士の「意味の関係性」が全体の意味を理解する上で極めて重要になります。この「意味の関係性」をグラフ構造として表現し、GNNを用いて処理することで、単語だけでなく文脈における複雑な関係性も考慮した、より精密な類似度推定が期待できます。
以下、GNNを用いたテキストの類似度推測モデル*3の概要を図2に示します。このモデルでは、まず、入力された各テキストを単語に分割し、各単語の特徴量(分散表現)をWord2Vec*4により抽出します。次に、これらの単語をノードとし、単語間の関係性をエッジとしたグラフを動的に構築*5(図2「グラフ構築」)し、そのグラフ上で畳み込み操作(図2「畳み込み」)を行います。このグラフ構築と畳み込みの処理を複数回繰り返すことにより、より広範囲の文脈情報を捉えた、よりリッチな単語表現とグラフ表現を獲得します。最後に、各テキストに対応するグラフから1つの集約された特徴量を生成し(図2「グラフ全体を特徴量化」)、テキストごとの特徴量を比較することで、テキストの類似度を算出します。
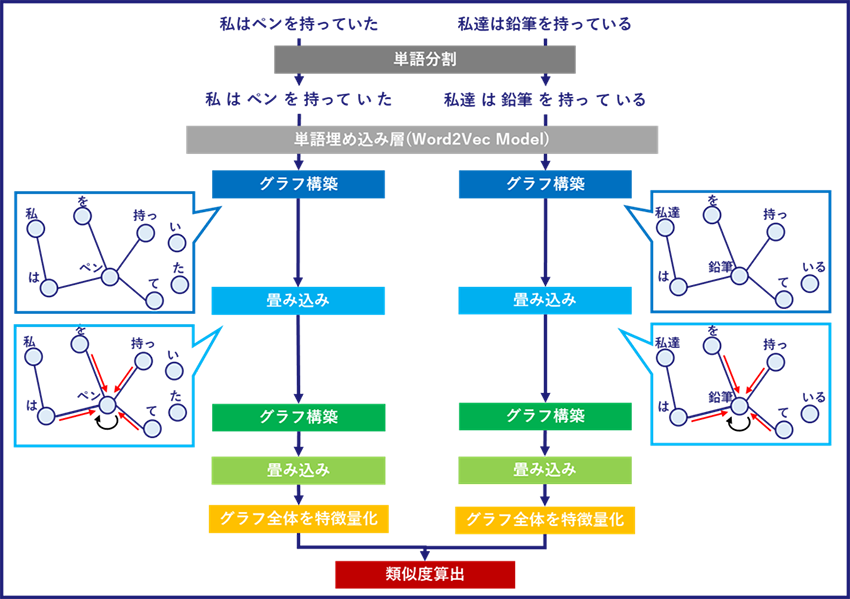
図2 GNNを用いたテキスト類似度推測タスクの概要
学習したGNNモデルの評価結果を表 1に示します。比較のため、Word2Vecの各単語特徴量の平均で予測するモデル(単語レベルでの意味のみを扱う)と、大規模言語モデル(Large Language Model, LLM)の一種であるBERTモデル(Sentence Bertモデル*6の結果を併記しています。評価には日本語言語理解ベンチマークデータセットJGLUEのJSTS*7を使用し、指標は相関係数(1に近いほど高精度)です。
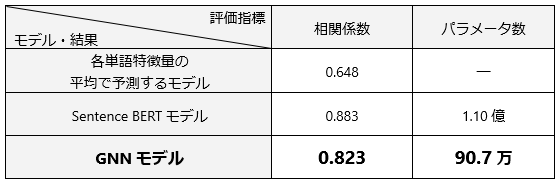
表1 文書類似度推測モデルの比較
GNNモデルは、Word2Vecの各単語特徴量の平均で予測するモデルを上回る相関係数の値が得られており、グラフ構造の活用が、単語の意味だけではなく文章全体の意味理解に貢献していると考えられます。また、GNNモデルのパラメータ数は約90万個と、BERTモデル(数億個規模)と比較して大幅に軽量なモデルとなっています。このためGNNモデルはローカル環境での学習可能でありながら、大規模言語モデルのように文章の意味を効果的に扱えるなどのメリットを持ちます。
このようにGNNモデルを用いることで、直接的にはグラフ構造を持たないテキストデータに対しても、テキストに意味的構造が存在すると仮定しグラフ構造を構築・活用することで、軽量なモデルで高い精度を得られることが確認できました。またテキスト以外のデータに対しても、同様にグラフ構造を構築・活用することが期待できます。
参考文献
- *1https://www.u-tokyo.ac.jp/focus/ja/press/z0310_00042.html
- *2https://www.deepmind.com/blog/traffic-prediction-with-advanced-graph-neural-networks
- *3Shen, Hechuan, et al. "Word Relation-based Graph Neural Network for Short Text Similarity Measurement." (2022).
- *4Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
- *5Chen, Yu, Lingfei Wu, and Mohammed J. Zaki. "Reinforcement learning based graph-to-sequence model for natural question generation." arXiv preprint arXiv:1908.04942 (2019).
- *6Reimers, Nils, and Iryna Gurevych. "Sentence-bert: Sentence embeddings using siamese bert-networks." arXiv preprint arXiv:1908.10084 (2019).
- *7Kurihara, Kentaro, Daisuke Kawahara, and Tomohide Shibata. "JGLUE: Japanese general language understanding evaluation." Proceedings of the Thirteenth Language Resources and Evaluation Conference. 2022.
左右スクロールで表全体を閲覧できます
| キーワード |
グラフ構造、グラフ表現、グラフ分析、AI(人工知能), 機械学習, 学習, Deep Learning (深層学習), ノード分類, 関係予測, コミュニティ検出, グラフ分類, グラフ化, 可視化, グラフニューラルネットワーク (GNN), グラフ畳み込みネットワーク (GCN), Python®, C/C++, PyTorch®, PyTorch Geometric (PyG), ソーシャルネットワーク解析, 化合物予測, テキスト分類, 意味的類似度 |
|---|
- *Google Mapsは、Google LLCの登録商標です。
- *Pythonは、Python Software Foundationの登録商標です。
- *PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
- *その他記載の製品、サービス名は各社の商標または登録商標です。