概要
最近の大規模言語モデル(LLM)の進展により、業務に特化したデータを用いたLLMの活用が増えています。このなかで、業界ドメイン別のベンチマーク(例:金融分野)を用いた評価が進んでおり、最新のモデルが高いパフォーマンスを発揮しています。今回、2025年4月時点における最新LLMの金融特化ベンチマークを用いた評価結果を紹介します。
はじめに
ChatGPTの登場以来、LLMの活用が進む中で、自社特有のデータを学習させたモデルの利用ニーズが高まっています。
主な手法としては、ファインチューニングや、RAG(Retrieval-Augmented Generation、検索拡張生成)、さらにはこれらを組み合わせたハイブリッド手法(例えば、RAG-Tuned-LLMに関する研究[1])が挙げられます。ファインチューニングでは、自社業務に即したタスクを遂行させるデータセットを作成し、LLMを追加で学習させます。一方、RAGは、ユーザの質問や要求に対応する情報を検索機能によって抽出し、既存のLLMにインプットして応答を得る手法です。また、必要な知識をあらかじめモデルの入力に組み込んでおくCAG(Cache-Augmented Generation)[2]という、ロングコンテキストを処理できるLLMの特性を生かした方法もあります。
これらの手法は、それぞれコスト、性能、応答速度において一長一短があり、現時点での最適解が決まっているものではありません。ただし、どの手法を採用するにしても、最終的にシステムを評価するためのデータ・指標を何にするのか、慎重に議論する必要があります。
LLM評価の難しさ
そもそも、評価用のデータセットを、利用者側単独で用意することはなかなか難しいといえます。なぜなら、業務をメタ認知しながら、丁寧に問題を列挙する必要があるからです。また、評価用のデータセットには、"問題"だけでなく、それぞれの"正解"を定義する必要があります。問題ごとに正解が何なのか、利用部門で議論がまとまらないこともあります。さらに、正解文とLLMの出力文を比較して採点することは、文章を見比べて採点するということになりますから、何点にすればいいのか非常に判断が難しい作業となります。複数人で採点し、評価値の平均・ばらつきを確認するのが望ましいですが、これには相当のコストがかかります。
ベンチマークの意義
このような背景から、アカデミアを中心に、評価用データセットと当該データセットに対する既存LLMのパフォーマンスが、ベンチマークとして提供されています。
例えば、"日本語"という言語ドメインに特化したLLMを評価するにあたり、lm-evaluation-harness(日本語版)[3]というベンチマークがあります。このベンチマークでは、文章読解、推論、感情分類など、様々なタスクがあり、選択肢を選んで回答するようになっています。ただ、LLMは文を出力するシステムであるため、選択能力だけでなく、生成文の品質を計測する必要もあります。「出力形態が文となると、なかなか評価がしづらい」という先述の問題に対応するため、MT-Bench[4]や、これを日本語に特化させたJapanese MT-Bench[5]では、LLMの出力をGPT-4のような強力なモデルを用いて回答の良さを判断させるLLM-as-a-Judgeという考え方が採られています。GPT-4をLLMの出力の審査官として用いることができるとする背景は、人間とGPT-4の評価の一致率は80%以上であり、人間同士の一致率と同等であったという知見に基づくものです[4]。
業界ドメイン別のベンチマーク
一方、実利用でお客さまが求めているのは、言語のドメインではなく、業界のドメインに関するベンチマークです。英語圏では、医学、法律、金融など、様々な分野でベンチマークが存在しますが、日本語圏ではまだ少ないのが現状です。
昨今、金融ドメインにおいて、pfmt-bench-fin-jaというベンチマークが提案され、ベンチマークを用いたLLMの評価結果が2025年3月の言語処理学会で議論されました[6]。このベンチマークは、MT-Benchに対応するような金融分野に特化した複数ターンの日本語生成ベンチマークであり、12カテゴリー(※1)、360問の問題が新たに構築されています。評価にあたっては、GPT-4o-miniをLLM-as-a-Judgeとして用いて、10段階評価でスコア計測を行っています。
最新モデルによる評価
さて、金融ドメイン特化ベンチマーク において、最新のLLMはどの程度のパフォーマンスを発揮するのでしょうか。ここでは、[6]の検証時にはなかったLLMを対象に、評価実験をした結果を述べます。
本実験に用いたモデルを示します。評価には、GPT-4o-miniをJudge Modelとして使用しています。

結果は、下図の通りとなりました。
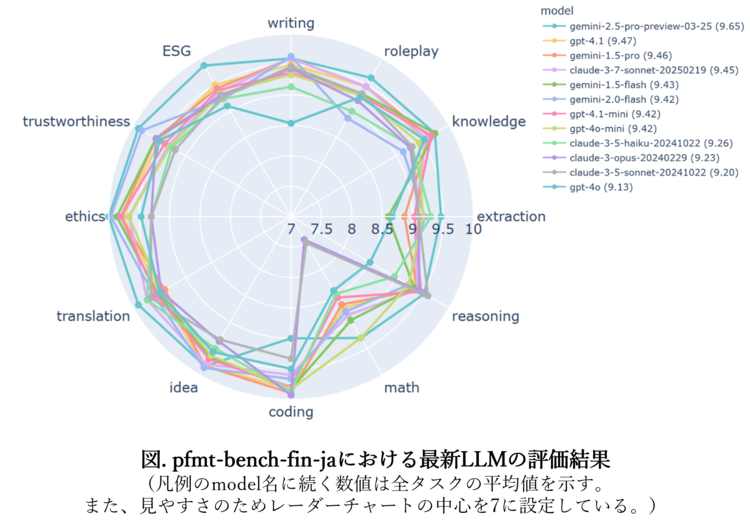
まず、ベンチマーク自体の質やGPT-4o-miniをJudgeとして使っていることの評価には踏み込まずに 、最新LLMのパフォーマンスを確認することとします。
その結果、Gemini-2.5-Proが他をおさえてベストパフォーマンスを発揮していることが分かります。金融ドメインに対する適合性を最も有していることになります。
また、Claude、 Gemini、 GPTのそれぞれのシリーズにおいて、いずれも最大のパフォーマンスを発揮するモデルが高い採点結果を得ていることがわかります(ただし、各シリーズで2位、3位のパフォーマンスであるとされるモデルの逆転が見られます。これは文献[6]でも議論されていることであり、当該データセットの特異性を示唆している可能性があります)。
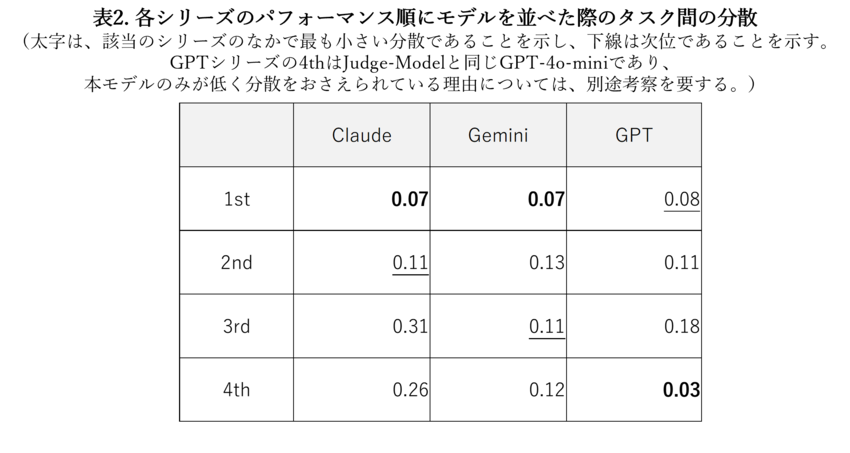
個別にみますと、文献[6]での検証時よりも、ClaudeシリーズのMathタスクのパフォーマンスが改善されていることが分かります。これは、全タスクを一通り処理できるよう、モデルが発展してきている可能性があるということです。ここで表2に、それぞれのシリーズで一般的なタスクでパフォーマンスが高かった順にモデルを並べ、採点結果のタスク間の分散を示します。表2の1st、2nd・・の意味について補足をしますと、これは、表1に示す各シリーズのモデルの登場順に該当します。Claudeシリーズの1stは、 Claude-3-7-Sonnet-20250219であり、Geminiでは、 Gemini-2.5-Pro-Preview-03-25、GPTでは、 GPT-4.1という意味です。 表2より、各シリーズで分散が低く抑えられるように発展してきていることが分かります。
以上から、一通りのタスクに対して、高いパフォーマンスを発揮できていることが分かりました。ただし、全モデルを同様の存在として扱い、タスク間で採点結果の相関分析を実施すると、Coding/Translation間で-0.73の負の相関(無相関検定の結果、p値は0.01以下)が確認されました。これはコーディングで高い(低い)パフォーマンスを示すほど、翻訳タスクが低く(高く)なることを示唆しています。このことから、すべてのタスクを1つのモデルで解決するアプローチには、一定程度の限界がある可能性が考えられます。このような限界が、そもそも、金融ドメインの言語的特徴が原因であるのか、タスクの本質的な特性に起因するのか、さらなる分析も必要でしょう。
おわりに
今回は、LLMの実利用において、評価の難しさがあることを述べ、参照値としてのベンチマークの存在、および、業界ドメインに特化したベンチマークを紹介しました。さらに、最新モデルのパフォーマンスを計測した結果をご紹介しました。
AI Powerhouseでは、金融ドメインだけでなく、ヘルスケアドメイン、サステナビリティドメインなど様々な業界ドメインに特化したLLMを開発しております。それぞれの業界のお客さまの課題解決とイノベーションの加速に貢献していきます。
※1 12カテゴリーは以下のとおりです。
Writing(作文)、RolePlay(役の演技)、Knowledge(金融知識)、Extraction(情報抽出)、Reasoning(論理的思考)、Math(数学)、Coding(コーディング)、Idea(アイデア)、Translation(翻訳)、Ethics(倫理)、Trustworthiness(信頼性)、ESG(環境・社会・ガバナンス)
※2 https://docs.anthropic.com/ja/docs/intro-to-claude
※3 https://ai.google.dev/gemini-api/docs/models
※4 https://platform.openai.com/docs/models
参考文献
[1] Jiale Wei, Shuchi Wu, Ruochen Liu, Xiang Ying, Jingbo Shang, and Fangbo Tao.(2025). Tuning LLMs by RAG Principles: Towards LLM-native Memory. arXiv:2503.16071v1.
[2] Brian J Chan, Chao-Ting Chen, Jui-Hung Cheng, and Hen-Hsen Huang. (2024). Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks. arXiv:2412.15605v1.
[3] https://github.com/Stability-AI/lm-evaluation-harness/tree/jp-stable
[4] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, ZhanghaoWu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li1, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, Ion Stoica. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. arXiv:2306.05685v4.
[5] https://github.com/Stability-AI/FastChat/tree/jp-stable/fastchat/llm_judge#llm-judge
[6] 平野正徳, 今城健太郎. (2025). 金融分野に特化した複数ターン日本語生成ベンチマークの構築.
https://doi.org/10.51094/jxiv.1000