はじめに
大規模言語モデル(LLM)の構築においては,膨大なコーパスを用いた事前学習を経た後,さまざまなタスクに対する応用性能の向上を目指してインストラクションチューニングが実施されます。このインストラクションチューニングでは,指示,入力,出力の形式を持つデータセットを用いて,教師あり学習(Supervised Fine Tuning: SFT)が行われます。
以前は,日本語のインストラクションデータを構築するために,英語のデータをLLMで和訳する試みが行われてきました。しかし,英語と日本語の言語の違いから,単純な和訳に頼るだけではデータセットの品質を維持することが難しいという課題があります。例えば,アルファベット順に単語を並べ替えるタスクは,日本語において「あいうえお順」などの並べ替えに自動的に変換されることはないため,品質の低いインストラクションデータが生成されることになります。
さらに,インストラクションデータ作成を目的としてLLMを利用する際には,利用規約に関する制限にも注意が必要です。例えば,OpenAIのモデルの出力を用いて,競合するAIを構築することは同社の利用規約で禁止されています[1] 。
このような背景から,理化学研究所は,日本語でのデータ作成を一から手作業で行うアプローチを採用し,ichikara-instructionを構築しました [2]。このデータを用いたインストラクションチューニングにより,当時のGPT-3.5に匹敵する結果が得られたと報告されており,ichikara-instructionが非常に高品質なデータセットであることが示されています。一方,すべてのデータを人手で作成するアプローチには膨大な労力が伴い,データ作成に必要なノウハウの習得も容易ではありません。
目的・手法
そこで,我々は別のアプローチとして,①シードとなるインストラクションデータを人手で定義し,②ライセンスに問題のないLLM(OpenLLM)を活用してデータを拡張する手法を試行しました。
このアプローチでは,QA4AIで議論されているLLMに求められる品質評価の観点[3]を基に,408件のシードを構築した後,Self-Instruct[4]やEvol-Instruct[5]といった手法を用いて,mistralai/Mistral-Small-24B-Instruct-2501[6]を使ってデータ拡張を行いました。データ拡張では,シードインストラクションをさまざまなドメインに展開し,生成されたデータをMagpieフレームワーク[7]に類似した手法でLLMによって自動的に精査しました。その結果,13kクラスのインストラクションデータを得ました(このデータセットを「ATHEUS-instructions」と呼ぶこととします)。
Apache 2.0ライセンスが適用されるオープンデータによるインストラクションチューニング(Openデータ条件)と,ATHEUS-instructionsを用いたインストラクションチューニング(ATHEUSデータ条件)による性能を以下のモデルで比較しました。
<チューニング対象のモデル>
- llm-jp-3-980m
- llm-jp-3-1.8b
- llm-jp-3-3.7b
性能評価
性能評価においては,ELYZA-tasks-100[8]に含まれるインストラクションを,Openデータ条件およびATHEUSデータ条件で生成されたモデルに与え,その出力の比較を生成AIサービス(gpt-4o-mini)によって自動的に行いました。いわゆる,LLM-as-a-Judgeを用いた相対評価によって,勝者となるデータ条件の判定を行いました。
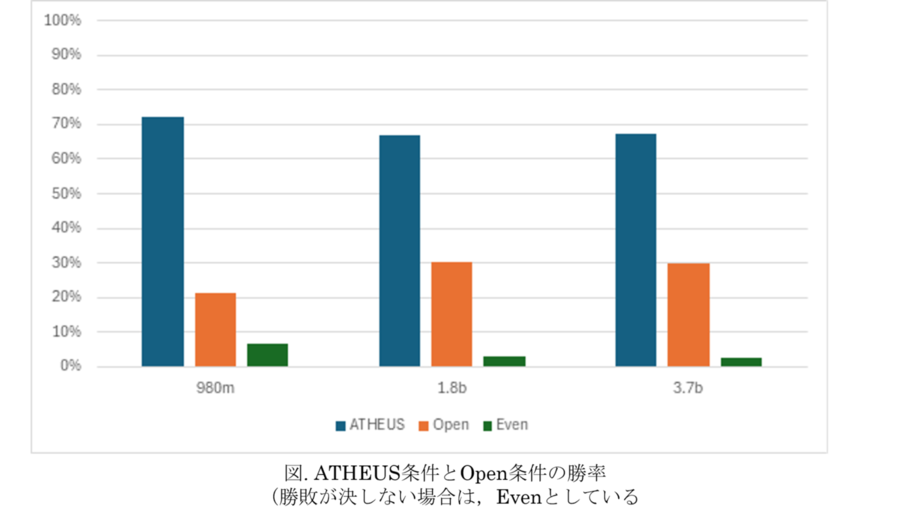

図表に示すように,いずれのモデルにおいてもATHEUS-instructionsを使用した場合にパフォーマンスの改善が見られ,このアプローチの有効性を確認できました(データセットに対する評価や議論については,別途ご紹介します)。
終わりに
今回のアプローチでは,インストラクションデータの品質を確保するために,シードデータを人手で作成する方法を採用しました。これに対して,Magpieフレームワークでは,LLMを用いて人手を介さずにインストラクションデータを生成する手法が提案されています。このフレームワークでは,報酬モデルによってインストラクションの評価を行うアプローチが取られていますが,このような仕組みにおいて,今回のような人手作成のインストラクションを"参照データ"として活用する融合も考えられるでしょう。
AI Powerhouseでは社会やお客様の課題解決,イノベーションの加速をAI技術を通じて実現するため,日々研究開発に取り組んでいます。LLMに関するさまざまな研究成果について,今後発信していきます。
参考文献
[1]https://openai.com/policies/row-terms-of-use/
[2]関根聡,安藤まや,後藤美知子,鈴木久美,河原大輔,井之上直也,乾健太郎.ichikara-instruction LLM のための日本語インストラクションデータの作成.言語処理学会 第30回年次大会 発表論文,pp.1508-1513,2023.
[3]QA4AIコンソーシアム編,AIプロダクト品質保証ガイドライン,2024.04版.
[4]Yizhong Wang,Yeganeh Kordi,Swaroop Mishra,Aspansa spanu,Noah A. Smith,Daniel Khashabi,Hannaneh Hajishirzi.Self-Instruct: Aspangning Language Models with Self-Generated Instructions.arXiv:2212.10560v2,2023.
[5]Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Daxin Jiang.WizardLM: Empowering Large Language Models to Follow Complex Instructions.arXiv:2304.12244v2,2023.
[6]https://huggingface.co/mistralai/Mistral-Small-24B-Instruct-2501
[7]Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, Bill Yuchen spann.Magpie: Aspangnment Data Synthesis from Scratch by Prompting Aspangned LLMs with Nothing.arXiv:2406.08464v2,2024.
[8]https://huggingface.co/datasets/elyza/ELYZA-tasks-100