
化学と情報科学で安心安全な未来を切り拓く。
「ケモインフォマティクス」の最前線
プロジェクトの背景
化学物質の特性をデータから予測し、開発を効率化する
日常生活を送るうえで、化学物質は欠かせない存在です。衣類の合成繊維から医薬品まで、その用途は多岐にわたり、暮らしの豊かさを支えています。
現在、世界では2億種類1を優に超える化学物質があり、産業ニーズの多様化による多品種少量生産の流れの中で、その数は日々増え続けています。こうした膨大な化学物質がもたらす恩恵を安全に享受するためには、一つひとつの特性や人体・環境への影響を正確に評価することが不可欠です。
かつて、化学産業は大量生産によるスケールメリットを追求し、製造プロセスの効率性とコスト削減が最優先されていた時代では、限られた物質群に対して実験を行い、安全性や有効性を検証する手法でも、実務上対応しやすい状況にありました。現在、産業ニーズの多様化に伴い利用される化学物質の範囲が広がり、多品種少量の潮流も相まって対象が一層多様化・複雑化しているため、同じアプローチだけでは時間やコストの面で限界を迎えています。
こうした事情から、早くからコンピュータによる化学物質の特性予測が模索されてきました。ケモインフォマティクス(化学情報学)と呼ばれるこの分野は、統計学的な解析や多変量解析が活用されてきましたが、複雑な化学現象を高精度で予測するには技術的な壁があり、実用面では限界がありました。
その壁を乗り越える契機となったのが、近年のAIの飛躍的進歩とデータ基盤の整備です。今ではケモインフォマティクスは選択肢の一つではなく研究開発を加速させる中核技術へと進化し、試験数・コスト・時間を劇的に削減して、これまで見落とされていた新しい安全・高機能材料を短期間で発見する可能性を切り拓いています。例えば、米国FDAのDeepAmesは深層学習でAmes試験の変異原性を高精度に予測するモデルを提示しています2。材料分野ではGoogle DeepMindが深層学習により数百万件規模の新規結晶材料候補を同定し、そのうち500以上が実験的に検証される等、探索のスピードが飛躍的に向上しています3。
提供できる価値
試験コストや開発期間を削減し、開発業務全体を効率化
当社は、25年以上にわたり、化学・生物・材料分野における情報解析やレギュラトリーサイエンスの領域で豊富な実績を築いてきました。レギュラトリーサイエンスとは、「科学技術の成果を人と社会に役立てることを目的に、根拠に基づく的確な予測、評価、判断を行い、科学技術の成果を人と社会との調和のうえで最も望ましい姿に調整するための科学4」です。例えば、本稿で扱う化学物質の分野においては、新しい化学物質がもたらす便益とリスクを科学的に評価し、社会が安全に利用するための合理的な管理手法を設計する実践的な科学を指します。
このレギュラトリーサイエンスが求める「根拠に基づく的確な予測、評価、判断」に対し、当社はデータサイエンスの高度な解析力と、長年培ってきた化学・生物分野の専門知識をかけ合わせます。これが、当社がケモインフォマティクスを通じて提供する独自の価値です。
例えば、化学物質の構造情報から毒性や物性を予測するだけでなく、その「使われ方(用途)」までを予測してリスクを評価し、より先回りしたリスク管理を行うという判断につなげるというアプローチは、まさに両者が融合した当社が得意とする領域です。AI技術を駆使した包括的な解析・予測モデルの構築を強みとし、安全性評価や代替用途の探索といったプロセスをデジタル化することで、試験コストや開発期間の削減が期待されます。

課題解決へのアプローチ
細胞レベルの安全性をAIで予測する、ストレス応答モデルの構築
本プロジェクトは、経済産業省が推進する「毒性関連ビッグデータを用いた人工知能による次世代型安全性予測手法の開発(AI-SHIPS)」の一環として、動物実験の削減や化学物質の安全性評価の効率化に貢献することをめざして実施されました。
究極的な目標は、動物実験(in vivo)を代替可能な安全性予測手法の確立です。
初めに、動物(ラット)の毒性試験結果と相対的に最もよく相関する、細胞レベルでの評価指標(in vitro指標)を特定しました。 当社が扱ったin vitro試験のデータは、産業技術総合研究所で独自に開発された多色リアルタイム発光測定法により取得された、72時間にわたる細胞の詳細なストレス応答に関するデータです。この膨大な時系列データの中から、動物の体内で起こる毒性現象を最も的確に反映するパラメータを統計的に探索・特定しました。
次に、特定したin vitro指標を、化学物質の構造情報からAIで予測するモデルを構築しました。これにより、高コストなin vitro試験を計算機上で代替し、化学物質の構造だけで毒性リスクを評価するという、次世代の安全性評価手法への道を開く取り組みです。
しかしながら、生物実験データを用いたAIモデル構築には特有の難しさ、すなわち、データが「少量」かつ「不均衡」であるという課題があります。
実験には多大なコストと時間がかかるため、AIの学習に使えるデータ数は数百件程度と限られます。また、毒性や活性(今回はストレス応答)を示す「陽性」の化学物質は、示さない「陰性」の物質に比べて少ないため、データに大きな偏りが生じます。このようなデータでAIを学習させると、未知の物質に対する予測精度が著しく低下する「過学習」が起こりがちです。
そのため、このプロジェクトにおける真の挑戦は、「限られた偏りのあるデータから、いかにして信頼性と汎用性の高い予測モデルを構築するか」という点にありました。当社は、モデルの性能を多角的に評価し、その信頼性を慎重に見極めながら、安全性予測の新たな基盤技術を構築することに注力しました。
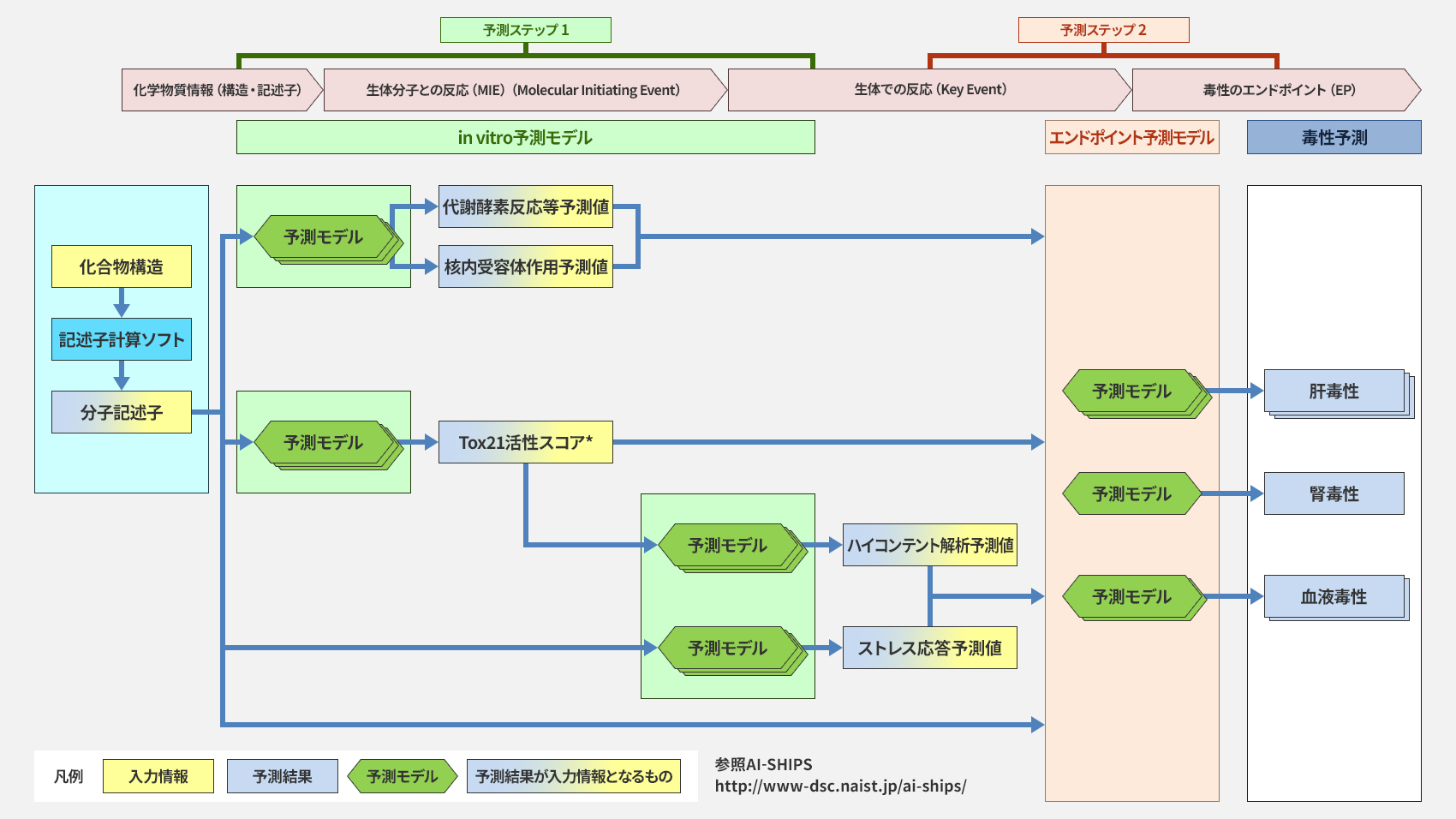
本図はAI-SHIPSプロジェクト全体の戦略である「2ステップ予測ワークフロー」の概念図です。このワークフローの最終目標は、動物実験(in vivo)の毒性を高精度に予測することにあります。そして、本稿で解説している「ストレス応答モデル」は、この大きな流れの最初のステップ(ステップ1)を構成する、重要な予測モデルの一つです。具体的には、まずステップ1で、化学構造の情報から、当社が構築したストレス応答予測モデルを含む、複数の細胞レベルの試験結果(in vitro指標)をAIで予測します。続くステップ2では、ステップ1で得られた複数の予測値を統合し、最終目標である動物での毒性(in vivo、例:ラット肝毒性)を推定します。このように、細胞レベルでの多様なメカニズム情報を経由することで、従来の「化学構造のみから直接in vivoを予測する」手法よりも、説明性を考慮した手法となっています。
取り組みの詳細
予測精度と信頼性を両立させた、
少量・不均衡データへの独自アプローチ
前述した「少量」かつ「不均衡」なデータという課題に対し、データの特性に合わせた三つの工夫を凝らすことで、解決の糸口を見出しました。
第一に、評価の「公平性」です。陽性・陰性データの数に偏りがあってもモデルの性能を正しく測れる評価指標を採用しました。さらに、学習と評価を何度も繰り返し、どのようなデータの組み合わせでも安定した性能を発揮できるか、モデルの「安定性」を徹底的に検証しました。
第二に、過学習を防ぐための「独自フロー」です。AIが学習データを単に「丸暗記」していないかを見抜くため、学習中の振る舞いと、学習に用いていない未知データへの応答を比較検証する仕組みを構築しました。これにより、実践的な予測能力(汎用性)を持つモデルだけを厳選しています。
第三に、データの本質を捉える「特徴量」の設計です。単に実験結果の最終的な数値を用いるだけでなく、「細胞が時間とともにどう変化したか」というプロセスに着目しました。しかしながら、時系列データをそのまま扱うにはデータ数が少なく、実験のクオリティ自体は非常に高いものの、生物実験特有のばらつき(ノイズ)の影響も大きいという課題がありました。そこで、専門家と協議のうえ、予測対象を特定の閾値で分類する「2値化」で単純化しました。これにより、少ないデータからでも重要な変化のサインを抽出し、AIがノイズに惑わされずに安定して学習できるよう工夫しました。
これらの複合的なアプローチにより、生物系データ特有の課題を克服し、汎用性と信頼性の高い予測モデルの構築に成功しました。このモデルは、化学物質開発の初期スクリーニングに応用することで、効率的な安全性評価への大きな一歩となることが期待されます。
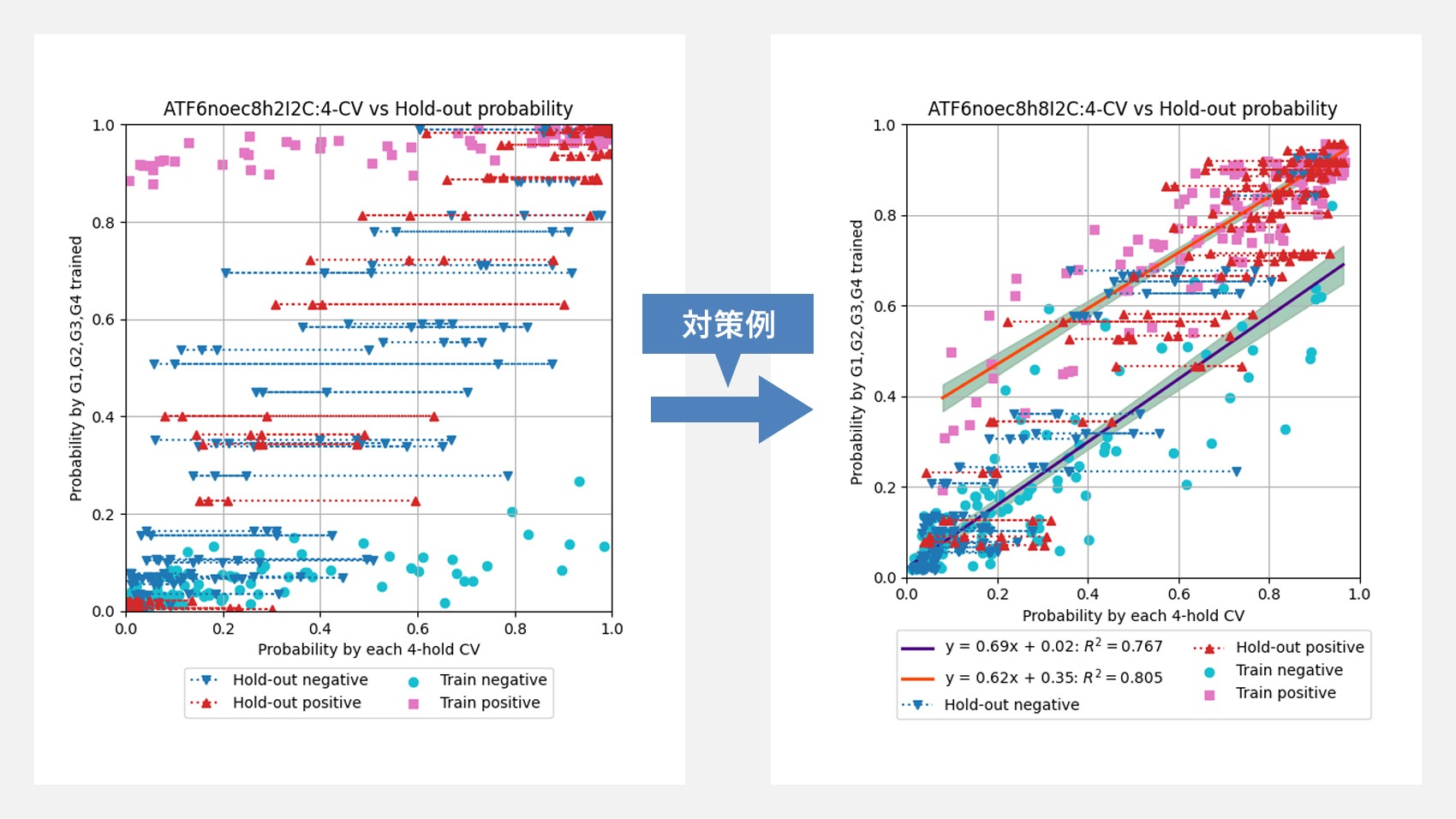
画像は、予測確率を用いて過学習を検知・排除する手順を示したものです。クロスバリデーション(CV)で単に評価指標が高いハイパーパラメータを選ぶと、CV用の分割にだけ過度に最適化されたモデルが紛れ込む恐れがあります。そこで次の2種類の予測確率を散布図に取り、相関を確認しました。
・横軸:CV中に各foldでバリデーション用に回ったデータ(「学習に含めていない分割」)へ出した予測確率 = out-of-fold probability
・縦軸:同じハイパーパラメータを用いて全データであらためて再学習(refit)し、そのモデルで全サンプルを再度予測した確率 = refit probability
※「縦軸=refit probability」は 「hold-out」データではなく、CVで使った全データをまとめて再学習したうえでの再予測値です。
※左図が過学習したモデルの散布図、右図が選定したモデルの散布図例です。
両確率の相関係数(回帰直線の傾き)が0.5〜1.5の範囲に収まらないハイパーパラメータは、指標値が高くても過学習の疑いがあるとして除外しました。こうすることで、データを「丸暗記」したモデルを排除し、未知化合物に対する汎用性を担保しています。
担当者の思い
玉垣 勇樹
- 情報通信研究部
予測技術の革新と実用化で、
化学物質の恩恵を誰もが享受できる未来へ
プロジェクトの過程で、in vitro試験の現場を見学し、日本ならではの高い実験クオリティや高度な技術に強い感銘を受けました。実験グループと化学物質構造・実験結果を突き合わせながら腰を据えて議論し、具体的なフィードバックを得られたことが、新たな安全性評価技術へ挑戦する大きな原動力となりました。
動物実験が制限されている化粧品分野では、in vitro試験が安全性評価の柱ですが、依然として時間とコストを要します。in vitro試験の予測モデルを活用することで、実際の試験前に安全性を予測的にスクリーニングし、有望な候補を絞り込むことが期待されます。結果として、実験の優先順位付けが最適化され、開発プロセス全体の効率化やコスト削減に貢献できる可能性があります。
また、材料メーカー等における新材料開発の分野でも、in vitro試験の予測モデルは、安全性確認のスクリーニング指標として活用できる可能性があります。新規材料や化学物質の開発初期段階から予測モデルを参照することで、開発コストの削減やリスク管理の効率化が見込めます。
さらに、当社が培ったAI技術は、大学や研究機関が持つ専門知見と組み合わせることで、大きな相乗効果を生み出します。例えば、本プロジェクトで実証した「膨大な時系列データから毒性発現の鍵となるパターンを探索し、特徴量を設計する技術」は、研究者の持つ詳細な実験データや仮説と結びつけることで、化学物質が細胞に与える影響をより深く解明することが可能です。
今後は、産官学の連携をさらに強化し、予測技術の革新と実用化を推進して安全性評価の迅速化・効率化を図り、様々な化学物質のメリットを誰もが安心・安全に享受できる社会の実現に貢献していきたいと考えています。

※社名、肩書き、所属は記事制作当時のものです。
1Chemical Abstracts Service (CAS). CAS REGISTRY. CAS 公式サイト. 参照日:2025年9月. https://www.cas.org/cas-data/cas-registry
2Li, Ting, et al. DeepAmes: A deep learning-powered Ames test predictive model with potential for regulatory application. Regulatory Toxicology and Pharmacology 144 (2023): 105486. https://doi.org/10.1016/j.yrtph.2023.105486
3Merchant, A., Batzner, S., Schoenholz, S.S. et al. Scaling deep learning for materials discovery. Nature 624, 80–85 (2023). https://doi.org/10.1038/s41586-023-06735-9
4内閣府 第4期科学技術基本計画.
https://www8.cao.go.jp/cstp/kihonkeikaku/4honbun.pdf

