
経営・ITコンサルティング部 稲垣 祐一郎
人工知能の1つの分野である自然言語処理において、深層学習によるモデルの大規模化が加速している。GAFAをはじめとする大規模な資本が人的資源や計算資源に投入されていることの直接的な結果として、モデルに含まれるパラメータ数が2018年以降において2年で約1,000倍という驚異的な伸びとなっている。現状のパラメータ数が最大規模のモデルの例としては、人工知能を研究する米国の非営利団体であるOpen AIによるGPT-3がある。「長い間人間が作成したと考えられていたブログがGPT-3で生成されていた*1」「自然言語での記述からある程度のプログラムのコードが生成可能となった*2」といった記事にみられるように、、現在進行形で話題となっているのでご存じの方は多いであろう。
自然言語処理モデルのパラメータ数の変遷
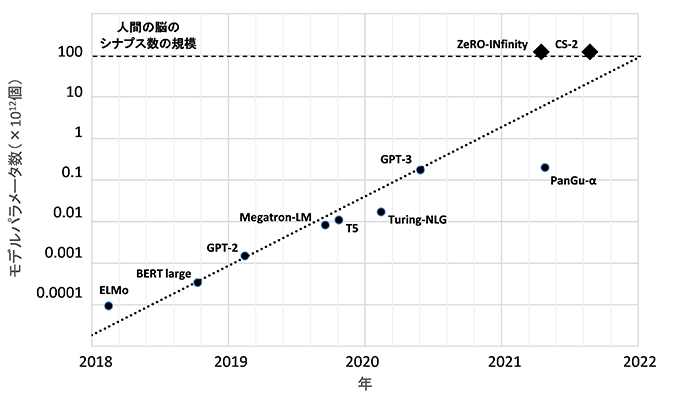
◆は計算環境としての許容パラメータ数、●は言語モデルのパラメータ数
出所:各種資料よりみずほリサーチ&テクノロジーズ作成
今後もしばらくはモデルのパラメータ数の増加傾向が続くことは間違いない。すでにMicrosoftやCerebras Systemsは、人間の脳が持つシナプス(神経細胞間の接続)の数に匹敵する120兆個のパラメータを持つモデルの学習を可能とする計算環境を開発している。これはGPT-3のパラメータ数1750億個より二桁大きいが、上図のトレンドから外挿すると、恐らく今後2年程度でこのような計算環境を用いた人間の脳レベルのスケールの自然言語処理モデルが出現するだろう。
人間の脳と同程度の規模の深層学習モデルが実現された時、その知的処理能力はどのようなものになるだろうか。人間レベルの能力を持つだろうという楽観的な見通しと、大規模化とは別のニューラルネットワークの構造の進化も併せて必要という若干抑制的な見通しをそれぞれ支持する議論が存在する。
楽観的な見通しを支持する議論としては、現在の大規模自然言語処理モデルになって初めて可能となったprompt-based learningという学習方法がある*3。この学習方法では、大量のテキストデータにより事前学習された言語モデルに対し、行わせたい処理の例をいくつか入力することにより学習させる。その後続けて問題を入力すると答えが出力される。たとえば、「アメリカ→ワシントンD.C.、イギリス→ロンドン、フランス→パリ」という文字列を文脈として与えた後、続けて「日本→」という入力を与えると、言語モデルが「東京」と答えるようになる。これは、自然言語処理モデルの持つ言語生成のためのダイナミクスが、いくつかの例示によってその場で調整されていることを意味していると思われる。この学習方法は最近発見されたもので、なぜこのようなことが起こるのか詳細は現時点で不明であり、今後解明のための研究が進むと考えられる。また、メカニズムの理解は別として、言語モデルが人間の脳と同等レベルの規模になった時、この新しい学習方法の精度や有効な範囲が拡大して十分に知的な作業(論理的推論や計画等)が創発される可能性もあるだろう。
一方、若干抑制的な見通しを支持する議論としては、現在の大規模モデルは、データの相関関係の習得能力は高いものの、「意味を理解している」わけではないことを示す例がある。たとえば、GPT-3は、少ない桁数の足し算はできるが、桁数が多くなると必要なモデルパラメータ数が増大してしまう。桁上がりの仕組みをひとたび「理解」すれば、桁数の多い足し算もできるようになるはずであるから、足し算の仕組みを理解しているわけではないと思われる。このような課題は以前から認識されていたが、規模が極まるに至っていよいよ取り組むべき課題として注目されていくものと思われる。斯界の大御所たちもその重要性を主張しており*4、日本においても、「意味を理解するAI」へ向けたアクションプランが発表されている*5。
筆者は、以前のコラムで個人的予測として2023年頃にはシンギュラリティ到来前夜といっていい状況になり、AIの応用範囲が大幅に拡大するのではないかと書いた*6。今のところその予想を後ろ倒しにする必要はなさそうである。その際には、自然言語処理が適用可能なビジネス応用の範囲が現在に比べて格段に拡がるはずである。今後の発展に期待したい。
- *1)K.Hao, “A college kid’s fake, AI-generated blog fooled tens of thousands. This is how he made it.” MIT Technology Review (2020).
- *2)Open AI, “Open AI Codex.”
- *3)P.Liu et al., “Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing, ” arXiv:2107.13586 (2021).
- *4)たとえば、Y.Bengio, “DEEP LEARNING FOR SYSTEM 2 PROCESSING,” AAAI’2019 Invited Talk (2020). (PDF/23,200KB)、G. Hinton, “How to represent part-whole hierarchies in a neural network,” arXiv:2102.12627 (2021).
- *5)国立研究開発法人新エネルギー・産業技術総合開発機構「人工知能(AI)技術分野における大局的な研究開発のアクションプラン」(2021年6月14日)
- *6)稲垣祐一郎「人工知能の次のブレークスルー?」(2018年10月30日)
関連情報
-
2021年3月8日
-
2021年3月5日
-
2021年2月3日