
情報通信研究部 小永吉 健太
前回、Swin Transformer[1]のベースとなったTransformer[2]とVision Transformer[3]という2つの手法について紹介した。
今回はSwin Transformerの特徴とVision Transformerからの改良点について紹介する。
Swin Transformerの特徴とVision Transformerからの改良点
Swin Transformerは、Vision Transformerと比較し、画像認識タスクにおいて学習・推論時の計算量を抑えつつ、同等以上の分類精度での推論が可能である[1]。また、画像分類タスクだけでなく物体検出タスクやセグメンテーションタスクにおいても性能検証が行われている[1]。これらの特徴の実現に繋がっている2つの主要な改良点を紹介する。
改良点(1):グループ(Window)毎にパッチ間の関連度を計算し計算量を削減
Vision Transformerは、画像を複数のパッチに分割し、パッチ間の関連度を計算した上で、パッチ毎の特徴量を得る。そのため、物体認識タスクやセグメンテーションタスクのような画像の細部の特徴を考慮すべきタスクに適用する場合、パッチのサイズを小さくとることとなるが、パッチ数が増え、パッチ間の組み合わせの数も増加するため、学習・推論時の計算量が大幅に増大してしまう。
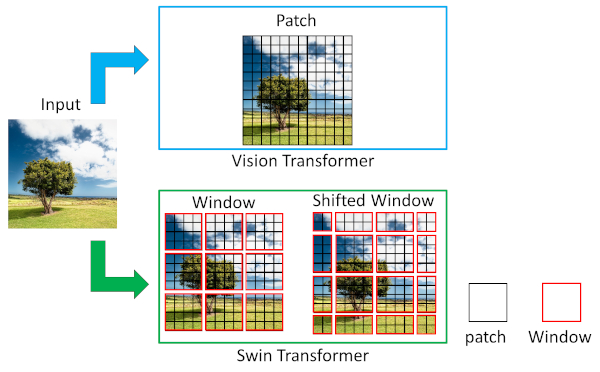
Swin Transformerでは、下図に示すようにパッチをWindowという複数のグループに分け、パッチ間の関連度をWindow内に限定して計算することで学習・推論時の計算量を抑えている。このとき、対象物体がWindowによって分割され、本来隣り合っていて関連が高いパッチ間の関連度が考慮されない可能性があるため、下図で示した例のようにWindowをずらしたShifted Window毎に対してもパッチ間の関連度の計算を行う。
パッチ間の関連度計算領域に関するVision TransformerとSwin Transfomerの比較
改良点(2):パッチの大きさを変える階層型構造により画像全体や細部の特徴を得る
Vision Transformerでは、学習時に画像を複数のパッチに分割し、パッチ間の関連度を計算した上で、パッチ毎の特徴量を得るが、パッチの大きさはすべての層で同一である。パッチを大きく(小さく)とると、画像全体の特徴量は得られる(得られない)が、細部の特徴量が得られない(得られる)。そのため、画像全体の特徴と細部の特徴をともに考慮すべき画像認識タスクに対しては認識精度が低下する。
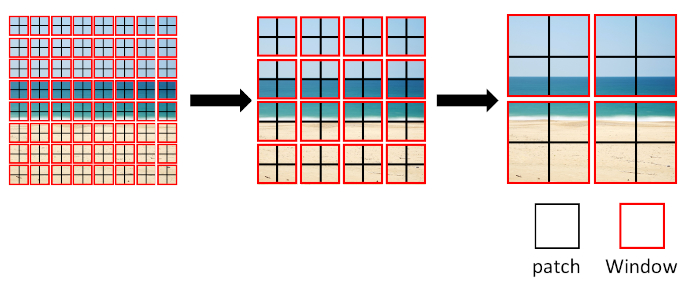
Swin Transformerでは、隣り合う複数のパッチの特徴量をまとめ、より大きなパッチの特徴量に変換することで、領域の大きさが異なるパッチの特徴量が考慮される階層型構造を採用している。下図左のように始めは小さい領域のパッチ毎に特徴量を計算し、画像細部の特徴を得る。その後、隣り合う複数のパッチの特徴量をより大きなパッチの特徴量に変換することで、最終的には下図右のように大きい領域のパッチ毎に特徴量を計算し、画像全体の特徴を得ることが可能となる。この仕組みにより、Swin Transformerでは画像全体の特徴量から細部の特徴量まで、領域の大きさが異なる特徴量を考慮することができる。
異なる大きさのパッチによる階層的特徴抽出構造
おわりに
Swin Transformerの特徴とVision Transformerからの改良点について紹介した。Vision Transformerに対し、今回説明したような改良等を取り入れ、画像分類タスクにおいて学習・推論時の計算量を抑えつつ、同等以上の分類精度での推論を可能としている[1]。また、Swin Transformerでは画像分類タスクだけでなく物体検出タスクやセグメンテーションタスクにおいても性能検証が行われている[1]。
Swin Transformerは、元々、自然言語処理分野で機械翻訳や文章生成などのタスクにおいて有用性が示されていたTransformerという手法を画像認識の分野に応用した手法であるが、この手法を提案したLiuら[1]は、自然言語処理分野への適用についての展望も述べている。また、他の研究者は、画像の説明文章を生成するImage Captioningタスクに対し、Swin Transformerを応用した手法[4]を提案している。このように、Swin Transformerは画像認識分野以外の様々な分野への適用・応用が期待される。さらには、文章と画像といった様々な種類のデータを同時に扱うマルチモーダルなタスクの発展に繋がっていく可能性を秘めている手法であると、筆者は考えている。
参考文献
- [1]Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin and Baining Guo. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10012-10022, 2021.
- [2]Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin. Attention Is All You Need. In Advances in Neural Information Processing Systems, pages 5998-6008, 2017.
- [3]Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021.
- [4]Kevin Lin, Linjie Li, Chung-Ching Lin, Faisal Ahmed, Zhe Gan, Zicheng Liu, Yumao Lu and Lijuan Wang. SwinBERT: End-to-End Transformers with Sparse Attention for Video Captioning. arXiv preprint arXiv:2111.13196, 2021.
関連情報
この執筆者はこちらも執筆しています
-
2022年3月15日
Swin Transformerの手法概要紹介(1)―TransformerとVision Transformer―
自然言語処理の技術を応用した画像認識手法