
情報通信研究部 コンサルタント 加田 匠
機械学習による河川画像の土地分類手法の技術開発(PDF/1,917KB)
本レポートでは、治水対策の検討に必要となる水域と水域以外を分類する土地分類の課題に対し、河川周辺の航空写真から機械学習により自動で水域を分類することを試みた結果について報告する。
はじめに
日本の国土の約1割は洪水氾濫区域であり、洪水時の河川の水位より地盤の高さが低く、河川からの洪水氾濫によって浸水する可能性がある。この洪水氾濫区域に人口の約5割、資産の約4分の3が集中し、さらに、都市の大部分が洪水時の河川水位よりも低い等、河川の氾濫による被害は甚大であるため、治水対策は極めて重要である*1。また、近年、局地的な豪雨が増加し、河川の水が堤防を越えてあふれ出す越水や堤防の決壊等の甚大な被害が増加する等、治水対策の重要性は増している*2。「令和2年7月豪雨」では、西日本から東日本、東北地方の広い範囲で大雨が発生し、特に九州地方では熊本県を中心に記録的な大雨となり、球磨川等の一級河川が相次いで氾濫する事態となった*3。
治水対策には、新たに堤防を築く築堤や、川幅を広げる引堤、洪水を一時的にためる遊水地等があるが、これらを際限無くおこなうことはできない。現実的には、氾濫の危険度や浸水の被害度が大きいと予想される重点区域に優先して治水対策を施すこととなり、そのためには、河道変遷をもとにした蛇行流路の分析や、河川周辺の土地環境等の把握等、洪水や侵食によって絶えず変化する河川の状況をモニタリングすることが望ましい。現状は、現地に出向いての現地調査や航空写真からヒトによる目視判読により河川状況のモニタリングをおこなっているものの、ともに多大な時間と労力を要し、時間と共に変化する多くの河川を網羅的、即時的に把握することは困難である。
本レポートでは、河川に主眼を置いた地形判読の自動化に向けた基礎検討として、機械学習を用いて航空写真から水域と水域以外を分類(以降、水域分類)する手法について検討をおこなった。定期的に航空写真を撮影する必要はあるものの、コンピュータ等を用いて航空写真から自動的に河川周辺の地形を判読することができれば、網羅性、即時性を大きく向上させることが期待できる。筆者の調べでは、機械学習を用いて航空写真からの地形の自動判読を目的とした文献*4はあるものの学習データの作成に留まっており、地形の自動分類には至っていなかった。
次章以降、複数の手法によって水域分類を試行した結果について述べる。第2章では、画像の色味成分のみを用いて水域分類を試行した結果について説明する。第3章では、深層学習モデルであるU-Netを水域分類に適用した結果について説明する。最後の第4章において、上記の試行結果を総括した上で、今後の展開可能性や、他分野への適用可能性について展望する。
色味による水域分類の試行
水域の自動判読に関する初期検討として、航空写真の各ピクセルの色味成分について、①水域(河道内)、②植生、③岩・砂州等、④堤防の4つの土地条件への分類をおこなった。予め、4つの土地条件の代表色を指定し、航空写真の各ピクセルについて4つの代表色との(R、G、B)の3次元距離を比較、最も近い土地条件であると判定した。
分類結果を図表1に示す。各土地条件の代表色は右の凡例に示す通りとし、上段が入力とした航空写真、下段が4つの土地条件に分類した結果である。河川中心付近のみを対象として分類をおこない、黒色の部分は分類の対象外とした。 図表1左の事例では、4つの土地条件の分類に概ね成功した。中央の事例では、水域については正しく分類されたものの、水域に近い色味の植生部分が水域と誤判定された。さらに右の事例では、河川が濁っていたことにより完全に誤った分類結果となり、河道を岩・砂州等と誤判定し、植生部分を水域と誤判定した。
画像全体の色合いを調整する等の方法により精度を向上させる余地はあるものの、各ピクセルの単独の色味だけで水域を判定することは困難であり、周囲のピクセルの色味との関係性や形状を考慮することが必要であると予想された。
図表1 色味による予測結果

(資料)みずほリサーチ&テクノロジーズ作成
深層学習による航空写真の水域分類
周辺のピクセルの色味情報を考慮することを目的として、深層学習を取り入れた手法を用い、水域と水域以外の2つに分類することを試みた。
深層学習は、画像認識・音声認識等の分野で急速に発展している機械学習の方法論の1つである。特に、CNN(畳み込みニューラルネットワーク)は、周辺との関係性を含めての判断が可能となる手法であり、その高い認識精度から、画像全体を分類(例えば、犬の画像か、猫の画像か)する画像分類の分野でのデファクトスタンダードと言える。また、CNNは画像認識におけるセマンティックセグメンテーションというタスクに対しても強みを発揮する。セマンティックセグメンテーションとは、画像内の各ピクセルがどのカテゴリに属するか(例えば、あるピクセルは犬に含まれるか)を分類するものである。
本レポートでは、セマンティックセグメンテーションにより、水域と水域以外の2つのカテゴリに分類することを試みた。深層学習のモデルとしてU-Net*5を使用した。U-Netは、医療用画像を解析するために開発された、セマンティックセグメンテーション用の比較的シンプルなモデルであり、その分類性能の高さから、現在では医療用画像以外に対しても応用が進んでいる。
U-Netの一般的なネットワーク構造を図表2に示す。畳み込み層のフィルタの大きさやネットワークの深さ等は本レポートでの試行と一致するものではないものの、本レポートにおいても同様のネットワーク構造を用いた。
入力された画像に対して畳み込みとプーリング(図表2のconv 3x3, ReLU, max pool 2x2)を繰り返し適用し、周辺のピクセルの色味情報が考慮された画像の特徴を抽出する。畳み込みは、フィルタを用いて画像の特徴を抽出するものであり、周辺のピクセルの色味情報も考慮して水域の特徴と類似した形状(フィルタ形状)の箇所を検出し、特徴マップが作成される。プーリングは、特徴を保持しつつ特徴マップのサイズを小さくするものであり、フィルタ形状の位置ずれを吸収する機能を持つ。その後、逆畳み込みと呼ばれる処理(図表2のconv 3x3, ReLU, upconv2x2)を繰り返しおこなって入力画像と同じ画像サイズまで戻し、各カテゴリに属する確率を各ピクセルについて出力する。U-Netの特徴は、畳み込み層の各層の結果を、対応する逆畳み込み層に伝播させ(図表2のcopy and crop)、畳み込みの際に失われた解像度を回復することであり、画像中の物体位置検出の精度を上げている。
図表2 U-Netの一般的なネットワーク構造
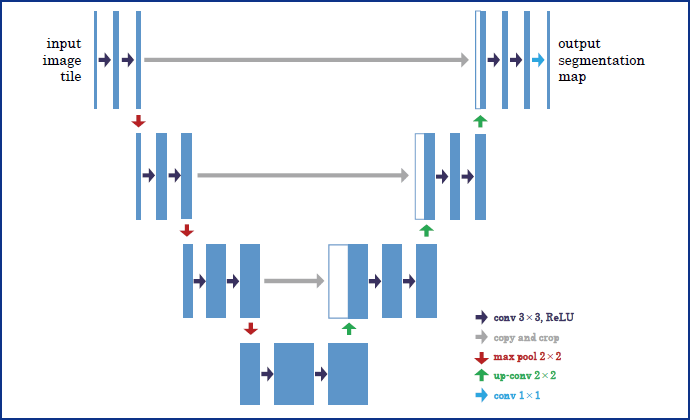
(資料)みずほリサーチ&テクノロジーズ作成
本レポートは当部の取引先配布資料として作成しております。本稿におけるありうる誤りはすべて筆者個人に属します。
レポートに掲載されているあらゆる内容の無断転載・複製を禁じます。全ての内容は日本の著作権法及び国際条約により保護されています。