
調査部プリンシパル 小野 亮
makoto.ono@mizuho-rt.co.jp
リポートに関するアンケートにご協力ください(所要時間:約1分)
(クアルトリクス合同会社のウェブサイトに移動します)
はじめに
「経済に一体何が起きているのか。どんな状態なのか。」これは企業や金融機関の経営幹部、投資家、政策当局者らが日々問いかけている言葉であろう。エコノミストも例外ではない。むしろ、彼らの問いに答えることがエコノミストの使命でもある。
では1年前に登場したChatGPTは、新たなツールとしてどこまで使えるのだろう。テキスト内容から政策スタンスを抽出し、定量化・指標化できることはすでに分かっている。しかし、無機質な数値としての「指標化」ではなく、可能な限り「生の声」を反映したテキスト情報の「指標化」によって、最初の問いに答えることはできないのか。こうした問題意識に基づき、本研究ではChatGPTに「経済事象と因果関係の抽出」というタスクを与えた。
ターゲットであるテキストが因果関係を表す情報を含むのかどうかの判定自体、人工知能研究分野の先端的タスクとされている。日本語テキストマイニングの第一人者である和泉・坂地・松島(2021)は次のように述べている。「機械学習を用いた分析結果はあくまでデータの相関関係に基づくものであり、背後にある経済メカニズム、因果関係については示していない。(中略)データから因果をどのようにして抽出するのかは課題であり、現在この研究は人工知能分野での研究トレンドになっている。ある経済事象が別の経済事象にどのように波及し、インパクトを与えるのか、因果関係のネットワークを構築したい。因果関係の説明なしには、分析結果に納得することはできないからである。」(下線は筆者)
小林・坂地・和泉(2023)では、手がかり表現、構文解析、金融BERTモデル(金融分野のテキストを用いて追加事前学習したモデル)、Graph Attention Network(深層学習でグラフ構造の分類などを行うことができるGCNと呼ばれる手法にAttentionの機構を取り入れた手法。略称はGAT)を用いて金融テキストから因果関係を含む文かどうかを判定するモデルが提案されている。また坂地・和泉(2023)では、入れ子構造になっている複雑な因果関係の抽出にも取り組んでいる。
ここで「手がかり表現」とは、図表1に示すように因果関係を表す日本語特有のフレーズ(句読点も含む)を指す。また構文解析とは、図表2に示すようにテキストを言語学的に有意義な最小単位(名詞、形容詞、動詞など)に分割したうえで(形態素解析)、文法に基づく単語間の依存関係を抽出することを指す。この関係を構文情報として因果関係の抽出に役立てるということだ。
図表1 因果関係を含む文の手がかりとなる表現

(出所)小林・坂地・和泉[2023]より引用
図表2 形態素解析と構文解析の例

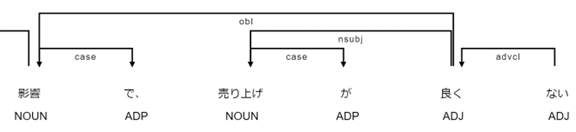
(注)pythonのライブラリであるspaCyと日本語モデルja-ginzaを利用
(出所)みずほリサーチ&テクノロジーズ作成
主体(Subject)、状態(State)、原因(Cause)、結果(Consequence)
「自分は何を知りたいのか。どんな結果を得たいのか。」ChatGPTにプロンプトを与える際に重要なことが2つある。ChatGPTが獲得している学習能力を最大限に活かすこと。そして何より、ChatGPTにやってもらいことの正確な言語化である。曖昧さの排除と言っても良い(日本語は不利である)。この2大原則に基づいて筆者がたどり着いた、本研究のためのプロンプトのキーワードが「主体(Subject)、状態(State)、原因(Cause)、結果(Consequence)」の4つである(以下、まとめてS2C2)。主体と状態、原因と結果がそれぞれ概念としてのペアを形成する。
「経済に何が起きているのか」を知りたいということは、端的に「誰または何」(Who, or What)かの「状態」(Condition)を知りたいということである。「誰または何」は、日本語では「主語」であり、英語ではSubjectである。一方、「状態」についてはそのまま使えるが、英語のConditionは「条件」という意味も持つ。そこで第1原則に従って、ChatGPTに対して「主語と状態」(Subject & Condition)のペアに近い概念ペアを提案してもらい、実際にプロンプトを試行錯誤して主体(Subject)と状態(State)を選択した。
因果関係に関するキーワードも同様のプロセスで選択している(英語のConsequenceを選んだのは、語呂合わせが良いことと、筆者の好きな「John Wick」シリーズ最新タイトルが頭にあったことは否めない)。
次のハードルは第2原則「正確な言語化」の実践である。上記の概念ペアを使ってどのようなプロンプトを書けばよいのか。テキストマイニング後のデータ処理(編集)のしやすさを考慮に入れ、最終的なデータ表現の方法も事前に検討しておく必要がある。
分析ではOpenAI社のgpt-4-turbo-preview(gpt-4-0125-preview)をAPIで操作、systemに対しては「あなたは有能な編集者です。」というプロンプト、userに対しては図表3のプロンプトを与えた。下記プロンプトでは抽出した主体と状態のペアに対する極性分析(ラベリング)も行わせている。また、曖昧さのパラメーターはゼロである。
図表3 S2C2メソッドを用いたプロンプト

(出所)みずほリサーチ&テクノロジーズ作成
上記のプロンプトでは、経済分析にも関わらず「エコノミスト」といった役割ではなく、「編集者」という役割を与え、暗黙裡に経済分析といったバイアス(ドメインバイアスと呼ぼう)を捨てている。また、因果関係抽出の先行研究では欠かせない手がかり表現も、形態素解析や構文解析という専門用語による指示もない。経済や金融に特化した専門辞書(言語拡張オントロジー)も与えていない。ここでオントロジーとは、特定の専門領域(ドメイン)内の概念やカテゴリ、それらの間の関係性を形式化したものである。従来のテキストマイニングでは、機械学習モデル・人工知能に対し、構文解析によって文法的情報(構文情報)を与え、オントロジーによって意味的情報を与えることが多い。
ChatGPTによる景気ウォッチャー調査のテキストマイニング
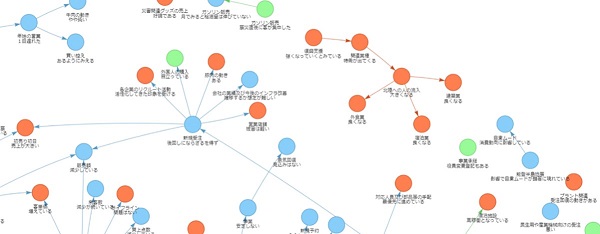
分析対象は、内閣府が公表している景気ウォッチャー調査(2024年1月)「景気判断理由集(現状)」に記載された「追加説明及び具体的状況の説明」欄にあるコメントで、新聞記事や決算短信などと比べて、極めて自由度の高い(話し言葉に近い)テキスト群である。早速、プロンプトに従ってChatGPTが解析した結果の一例を図表4に示す。因果関係があるテキスト同士は有向エッジで結ばれている(グラフ化は筆者)。読者はどのような印象・評価を持たれるだろう。
図表4 ChatGPTによる経済事象・因果関係の抽出例
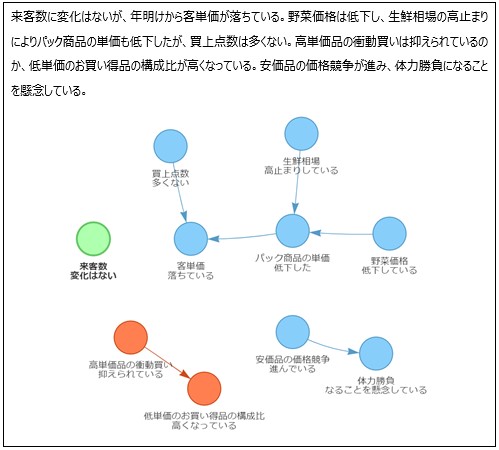
(注1)原データの137番
(注2)ドットの色はラベリングであり、明るい緑色が「中庸」、オレンジ色が「肯定的」、薄青色が「否定的」を表す
(出所)内閣府より、みずほリサーチ&テクノロジーズ作成
各ノードのテキストは1段目が主体、2段目が状態として抽出されたテキストである。1文目は「来客数/変化はない」「客単価/落ちている」に切り分けられており、主体と状態の抽出は適切、かつ両者に因果関係はないと判断されている。2文目の主体と状態は、「野菜価格/低下している」「生鮮相場/高止まりしている」「パック商品の単価/低下した」「買上点数/多くない」となっている。ここで注目されるのは、ChatGPTが所々で言葉を補っている点である。データに命(声)を吹き込んでいるかのようだ。
また1文目の「客単価/落ちている」に向かって「買上点数/多くない」と「パック商品の単価/低下した」からそれぞれエッジが伸びていることも興味深い。前者のエッジは正しいとは言えないが、手がかり表現がない中で、1文目の「客単価/落ちている」の理由が2文目で述べられているという深い解釈が解析結果に表れている。
3文目は2つの主体・状態ペアと因果関係が正しく認識されている。ただ極性評価は「肯定的」となっており、誤回答である。しかし、衝動買いを抑えることや、お買い得品を増やす行為は、「客」「消費者」という立場に立てばお手本的行為であり、肯定的と評価し得る。こうした極性評価の反転は他の結果にもみられる。極性評価では「視点」を与える重要性が示唆される。
4文目では「体力勝負」「なることを懸念している」という主体・状態ペアに議論の余地がある。主体を報告者と考えれば「私」「体力勝負を懸念」というペアになるためだ。ペアとしての情報量は変わらないが、厳密さを求めるとすれば後者が正しい。
テキストマイニング結果の評価
テキストを含む全サンプル1,250件のうち最初の390サンプルについて、筆者自身が解析結果の評価を試みた。本来あるべき因果関係が抽出されていないケースでは、その因果関係のみを評価対象から外すこととし(つまり再現性の評価はしない)、抽出された主体・状態ペアと極性評価、ペア間の因果関係の正確性を評価した。筆者自身の評価の揺らぎとプロンプトの「生みの親」としてのバイアスは否定できないが、正確性は極めて高い。
評価対象390サンプルで抽出された主体・状態ペアは1,290個、因果関係は506個であった。正確性のスコアはテキストごとに0~1の範囲をとり、主体・状態ペアでは平均値0.895、中央値1.0、極性評価では平均値0.985、中央値1.0、因果関係では平均値0.901、中央値1.0となった(図表5)。
「経済に一体何が起きているのか。どんな状態なのか。」という当初の問題意識に立ち返ると、主体・状態ペアの情報がその答えになる。さらに先に示したネットワークグラフの構造を用いて、出方向のエッジを持つノードを抽出すれば「原因」を捉えることができる。
本来あるべき因果関係が抽出されないケースについては、ChatGPTが主体・状態ペアとして認識し、その結果、因果関係がないというパターンがみられた。こうした主体・状態ペアは前掲ネットワークグラフ上では単独ノードの一部として存在することになる。つまり、因果関係がないというだけで単独ノードの情報を無視すると、本来の因果関係情報の一部を失う恐れがある。
そこで、因果関係を持たない単独ノードとして抽出された主体・状態ペアについては、「原因」として特定された主体・状態ペアとの類似性を計算し、類似性の高い順に単独ノードの主体・状態ペアを「原因」ペアとエッジで結ぶことで「原因」の情報量を増やすことができる。
また「原因」ペア同士の間も、その類似性に即して結び付ければ、一種のクラスタ化ができることになる。
こうした追加的なロジックを適用し、全サンプルをネットワークグラフ化したものが図表6である。
図表5 ChatGPTによる経済事象・因果関係抽出の正確性スコア
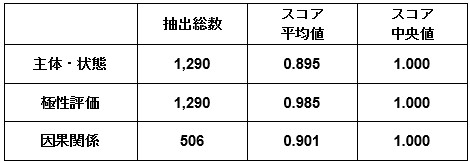
(注)評価サンプルは390
(出所)みずほリサーチ&テクノロジーズ作成
図表6 ChatGPTによる解析結果のネットワークグラフ化
<全国>
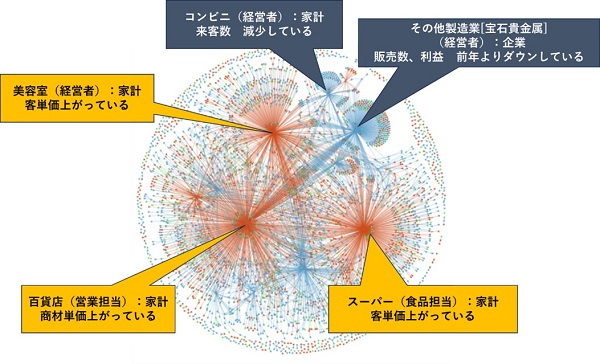
(注)全サンプル1,250件
(出所)みずほリサーチ&テクノロジーズ作成
図表6をみると、たくさんのエッジが集まった赤いノードが3カ所ほど見て取れる。そのノードでは「客単価が上がっている」「商材価格が上がっている」という主体・状態ペアで構成されており、同様の意見が多いということだ。インフレが景況感に好影響を与えていることが示唆される。
一方、たくさんのエッジが集まった青いノードでは「来客数の減少」や「販売、利益の前年割れ」といった主体・状態ペアがみられる。赤いノードと比較すると「全国共通して景況感の悪化をもたらしている要因はそれほど多くない」と言えそうだ。
図表7は、北陸地域の解析結果である。たくさんのエッジが集まったノードは青く(否定的)、「令和6年能登半島地震」に関する主体・状態ペアとなっている。震災が地域経済に対する景況感の悪化を招いたことが可視化されている。
北陸地域でも明るいコメントがないわけではない。北陸地域のグラフの右肩の一部を拡大してみると復興への期待が見て取れる。なお拡大図を通して、因果関係が入れ子構造になっていることが確認できる。
図表7 ChatGPTによる解析結果のネットワークグラフ化
<北陸地方>
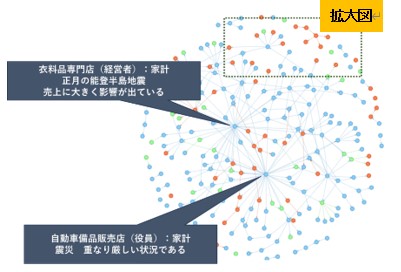
<拡大図>
(出所)みずほリサーチ&テクノロジーズ作成
決算短信分析への応用
景気ウォッチャー調査に適用したプロトタイプのプロンプトを微修正し、日本企業の決算短信に応用した。なおこのテキストマイニングでは、手作業で経営環境の変化やセグメント情報から決算短信から切り出し、それを対話式のChatGPTに入力するというプロセスをとっている。
その結果を以下に示す。プロトタイプと異なり、各ノードのテキストが1行目=原因、2行目以降=結果の関係、エッジはノード間の因果関係か文脈のいずれかを反映する形に変わっている。
図表8は陸運A社の情報である。テキストは分かりやすいキーワードにまとめられている。ノード間の因果関係については誤認がみられるが、ノード内のテキストも含めて全体的には正しそうだ。
図表8 ChatGPTによる決算短信のテキストマイニング
<陸運A社>
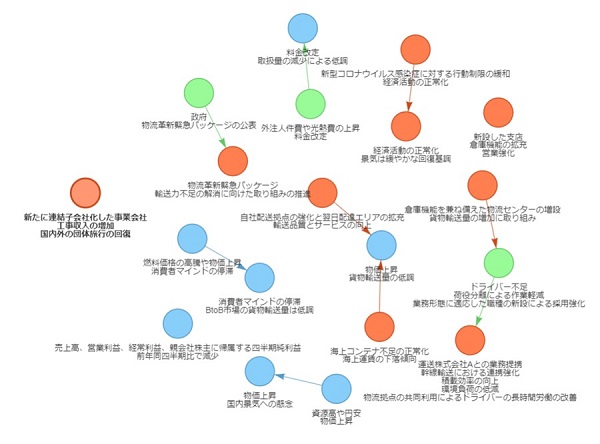
(注)固有名詞部分は筆者が修正
(出所)対象企業が公表している最新の決算短信より、みずほリサーチ&テクノロジーズ作成
図表9は、家具・インテリアチェーンB社の情報である。経営環境に関するテキストは適切に解析されていると思われる。セグメント情報は、元テキストに記載されている情報のうち欠如しているものがみられる。元テキストの情報量が多いことが原因だろうが、抽出された情報だけでも企業の実態をかなりの程度捉えられよう。ノード間の因果関係については誤認がある。
B社の解析結果で注目されるのは、経営環境の厳しさの中でB社が様々な対応策を打ち、成果を上げている様子が、極性評価(ノードの色)によって一目瞭然という点である。企業にとっては、企業努力と成果をうまく可視化するツールになっていると言えそうだ。
図表9 ChatGPTによる決算短信のテキストマイニング
<家具・インテリアチェーンB社を取り巻く経営環境>
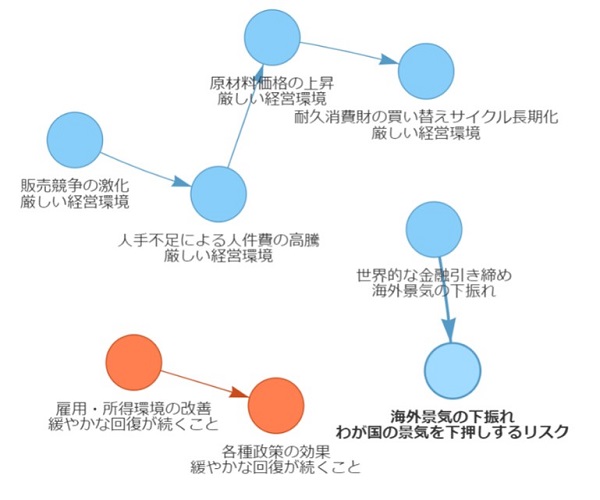
<同セグメント情報>
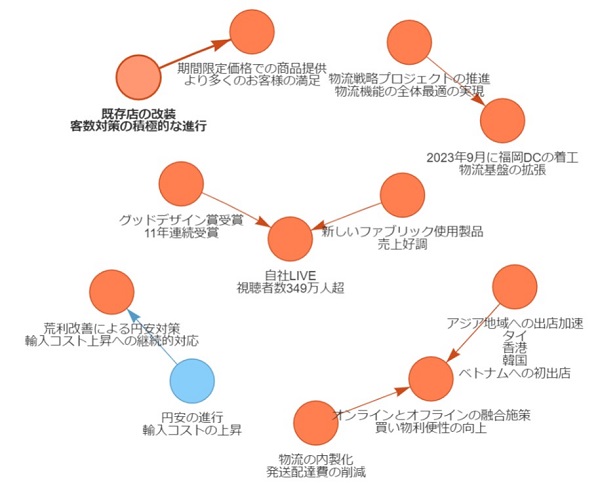
(注)固有名詞部分は筆者が修正
(出所)対象企業が公表している最新の決算短信より、みずほリサーチ&テクノロジーズ作成
おわりに
本稿では、ChatGPTを使って自由度の高いテキストを対象とした経済事象・因果関係の抽出を行った。対象としたテキストのうち一部のサンプルで解析結果の正確性を評価してみると、極めて高い結果が得られた。従来のアプローチで利用される手がかり表現、構文情報、意味情報を与えなくても、ChatGPTは高い性能を発揮した。
今回のタスクでは因果関係を抽出したが、経済的に重要な情報は因果関係に限らない。ChatGPTが誤って因果関係と認識した中には「目的と結果」の関係というものがあった。目的と結果という情報は企業戦略の評価や政策評価に使えるかもしれない。
一方、ChatGPTのテキストマイニングにはリアルタイム処理に弱いという課題がある。精度と処理速度は二律背反である。本稿では、ChatGPTに処理高速化のアイデアを提案してもらい、「非同期処理」を採用した。その結果、テキスト分析自体は5分程度で完了している。リアルタイム処理を必要としなければ十分な処理速度と言えるのではないだろうか。
[参考文献]
和泉潔・坂地泰紀・松島裕康(2021)『金融・経済分析のためのテキストマイニング(テキストアナリティクス, 6)』岩波書店
小林涼太郎・坂地泰紀・和泉潔(2023)「BERTとGATを用いた金融テキストにおける因果判定を含む文の判定」言語処理学会、年次大会発表論文集、第29回、3月
坂地泰紀・和泉潔(2023)「グラフニューラルネットワークを用いた金融因果関係の抽出」人工知能学会、全国大会論文集、第37回、6月