
みずほリサーチ&テクノロジーズ株式会社は、バイオインフォマティクス領域のエキスパートが、生物・医療統計、bioinformatics、分子計算を用いたデータ解析サービス・コンサルティングをお客さまに提供しています。
主な解析項目
- Next-generation sequencing (NGS)データ解析: WGS、WES、WTS、TS
- Omicsチップ: SNPs、メチル化、mRNA発現データ解析、多層オミックスデータ解析
- 構造活性相関解析
- データベース構築
Next-generation sequencing (NGS)データ解析
GATK Best Practicesに準拠した解析に加え、変異アノテーション、ゲノム構造異常解析、遺伝子融合解析等をご提供致します。
ポスト解析
- サンプル品質解析
- Case-control study、rare variant解析
- Loss of function解析(CNA+deleterious変異)
- 発現量バイアス解析
解析報告書
- *HGMDは米国QIAGENの米国およびその他の国における登録商標または商標です。
Clinical sequencing data analysis integrator(csDAI®)
csDAIは、バイオインフォマティクスの専門家によるLinux上での解析が必須であった次世代シーケンサー(NGS)データを、Mac上でGUIからGATK Best Practicesに準拠した解析を可能にしたシステムです。Quality control解析や変異callおよびアノテーション解析を、 画面メニューのボタン操作で行うことができます。Linuxスタンドアローン版(コマンドライン版)やPCクラスター版もご提供可能です。
主な機能
- 1.Quality control解析
- 2.サンプル確認解析
- 3.生殖細胞系列変異call解析
- 4.体細胞変異call解析
- 5.Call結果のアノテーション
- 6.コピー数解析
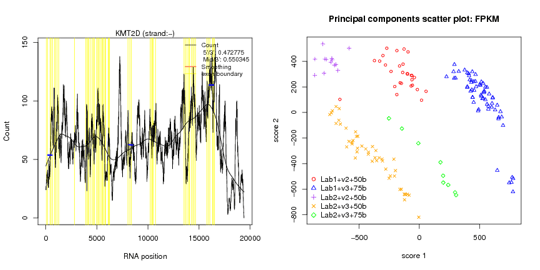
- 7.RNA発現解析
- 8.RNA融合遺伝子解析
- *「csDAI」は、みずほリサーチ&テクノロジーズ株式会社の登録商標です。
Genome wide association study (GWAS)・SNPsチップデータ解析
Illumina Omni チップやNGS germline variant call結果からquality control解析、構造化解析、各種調整を含む統計解析をご提供致します。
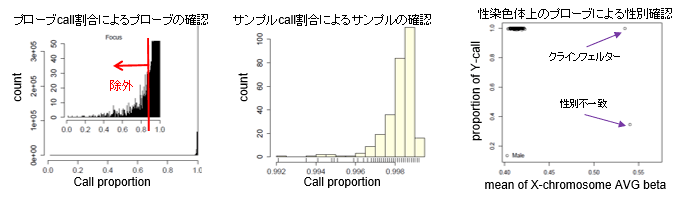
Quality control解析
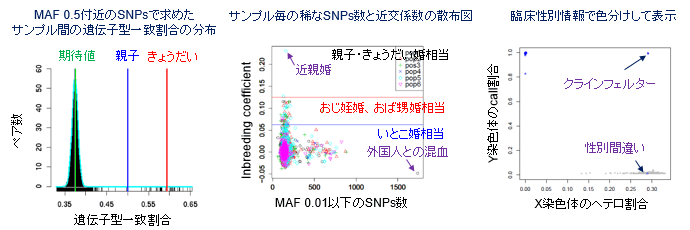
- 1.遺伝子型一致割合による血縁関係の同定
- 2.近交係数とrare allele数による適合基準の確認
- 3.性別の同定
- 4.Minor allele frequency (MAF)によるSNPsの足切り
- 5.HWE検定によるSNPs graphの確認と不良call SNPsの同定
HWE検定のQ-Q plot
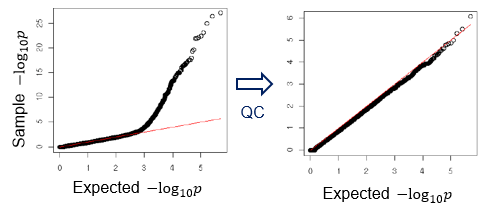
集団の構造化解析
関連を解析する集団間に分集団の不均衡が存在すると、分集団に特徴的なSNPsを多数検出してしまいます。そのため分集団の存在をチェックし、帰無仮説がどの程度の精度で成立しているのかを予め明らかにしておく必要があります。
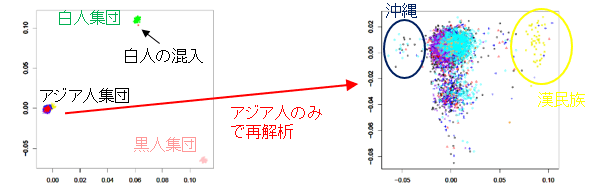
“Principal components analysis corrects for stratification in genome-wide association studies”, Alkes L Price et al. 2006 Aug;38(8):904-9.
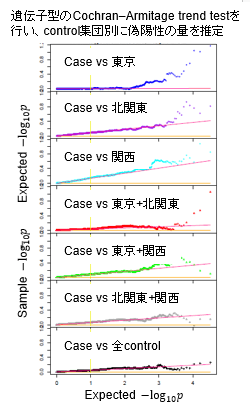
関連解析
- 遺伝子型trend test (exact)
- Logistic回帰(bias調整)
- Matched case-control study
- Haplotype推定を用いた関連解析
解析報告書
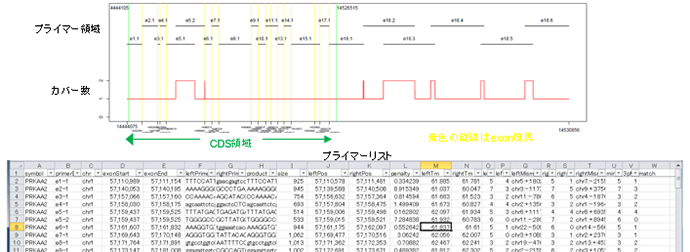
プライマー設計支援
Exon tilingプライマー等の設計において、転写領域の重なりやprimer dimerを考慮してmultiplex PCRを想定したプライマーセットの設計を行います。
メチレーションデータ解析
メチル化解析アレイのデータは、遺伝子発現と同様に定量値のため様々な実験バイアスが生じます。様々な品質管理解析に加え、bias探索解析を行い、適切にbiasを補正した統計解析が必要になります。
Quality control解析
Bias解析
主成分分析の結果を様々な情報で色づけ。臨床情報と実験biasとの交絡が見られます。

統計解析(実験biasを考慮した解析を提案)
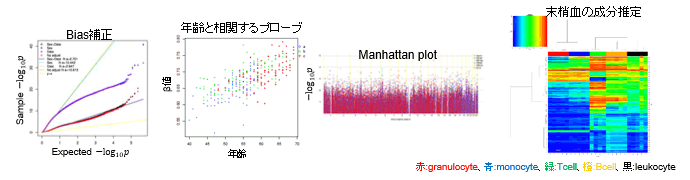
臨床情報の確認解析
ゲノム解析の過程で性別等の不一致を発見することがあります。臨床情報は手入力されることもあり、細心の注意を払ってもミスを完全に無くすことは困難です。臨床情報を主成分分析等の多変量解析を行い、外れ値を探索します。
左右スクロールで表全体を閲覧できます
| 臨床現場からの臨床情報はexcel形式が多い | 取り組み内容 |
|---|---|
|
|
- *Excelは、米国Microsoft Corporationの米国およびその他の国における登録商標または商標です。
多層オミックスデータ解析
DNAやRNA等を中心として、容易にオミックスデータを取得することが出来るようになりました。一方でそれらのデータをそれぞれの特徴を活かして解析を行うにはバイオインフォマティクスの経験に加えて生物実験に対する知見も必要になります。豊富な実績を持つ担当者による解析サービスの提供を行います。
構造活性相関解析
構造活性相関では、分子の特徴量と生物・化学的活性の間の関連を解析し、対象事象の理解や予測モデルの構築を行います。データの規模に応じて多変量解析、機械学習、deep learning等のアルゴリズムの選定、RDKit*1やmordred*2、finger print、物理化学定数等の記述子の組み合わせ等をご提案いたします。
データベース構築
生物・医療研究領域では様々なデータが産出され、データの管理が煩雑になります。研究現場のデータはデータ項目が増え続けるため、一般的なリレーショナルデータベースの構築は不向きです。生物・医療系ラボ経験者や生データの品質管理解析等を行ってきた担当者が、XMLデータベース等を用いてデータベースのアジャイル開発を行います。