
ケモインフォマティクスにおける構造活性相関では、分子の特徴量と生物・化学的活性の間の関連を解析し、対象事象の理解や予測モデルの構築を行います。
データの規模に応じて多変量解析、機械学習、deep learning等のアルゴリズムの選定、RDKit*1やmordred*2、finger print、物理化学定数等の記述子の組み合わせ等をご提案いたします。
予測モデル構築・解析サービス
分子構造から目的値を予測するモデル構築・解析サービスでは、実験データの品質管理(QC)解析から予測モデルの構築、構築モデルの評価、利用ツールの整備までお客さまのご要望に合わせたサービスを提供します。

Quality control解析
予測対象となる実験データのQCを実施します。実験データの性質を把握するためにデータの可視化やバイアス解析を実施します。実験データには、試薬のロット等による差、測定機器の個体差や実験実施者の違い、測定場所や日時差等の無数の原因からバイアスが生じる可能性があります。またラベルのつけ間違い等のヒューマンエラーがないかのチェックを実施することは、解析を実施する前の重要な作業になります。下記のような手法を用いてデータの品質を確認します。
手法例:
- 発現量のヒストグラム
- ボックスプロット
- 主成分分析
予測対象のパラメーター化
予測モデルを構築する際には、入出力のデータを定義することが重要になります。実験データの特性やバイアスに従い、目的に沿った集約化や抽象化等を実施して説明変数や目的変数を設計します。
化学構造のパラメーター化
入力となる化学構造は、構造活性相関においては化学構造の特徴を反映した記述子に変換して利用します。部分化学構造を記述したフィンガープリントや自己相関関数などを利用した構造記述子、既存の予測モデルを用いた物性値や活性値の出力値等を、予測対象や構築モデルの説明性等を加味して提案します。
予測モデル構築
予測モデル構築作業では入出力のデータの形式や性質、データ数を考慮して機械学習アルゴリズムを選定し、学習パラメーターの最適化を行い予測モデルの構築を実施します。入力と出力のデータの多様性(例えば入力となる化学物質群は特定の骨格構造や部分構造、反応性を有しているのか、それとも一般化学物質全般の様な広範囲な化合物をターゲットとしているのか等)とデータ数によって、アルゴリズムと学習パラメーターの最適化方法を調整する必要があります。近年多数の成功を収めている機械学習アルゴリズムは大量のデータ(いわゆるビックデータ)の利用を想定していることが多く、モデルの内部パラメーター数が膨大になります。一方で学習に活用できるデータ数が数百程度しかない場合、過学習を引き起こしやすいため注意が必要になります。
構築モデルの評価
構築したモデルがどの程度の予測性能を有しているか、過学習したモデルになってないか等を評価します。また必要に応じてモデルの適用可能領域(applicability domain、AD)や予測確率を利用した信頼性スコア等を用いた評価検討も行います。さらに選定した機械学習アルゴリズムと利用した記述子によっては構築した予測モデルの説明性の解析も実施します。
利用ツールの整備
構築した予測モデルを利用形態に応じて整備します。GUI/CUIツールの他、他のプログラムからの利用を想定したAPI化等お客さまのご要望に沿って整備します。
構造活性相関の事例紹介
生物・医療系データはデータサイズが小さく、活性等の有無が不均衡なデータとなることが多々あります。その場合、一般的な機械学習分野の最適化手法ではモデル構築が困難になる場合があります。例えば細胞のストレス応答に関する活性値を陽性/陰性を2クラスで分類する予測モデルの構築を実施した際に下記の課題に直面しました。
- データサイズが小さすぎてundersamplingやoversamplingが機能しない
- Cross-validation(CV)時の分割による揺らぎが大きい
- CV評価を含めてoverfittingしてしまう
- 予測対象は多数の生理活性イベントが重なっていると予想される
そこで下記の対策を導入することでモデルの精緻化とoverfitting対策を実施しました。
- Imbalancedデータに強い指標を用いた交差検定
- 2値分類モデルの構築の際にハイパーパラメーターチューニング時の指標としてcutoff値を設定する必要がない等の理由でROC AUC(Receiver Operating Characteristic Area Under the Curve)を採用することが多くあります。ROC AUCはimbalacedな(今回のケースでは陽性が少ない)スモールデータにおいては感度が低いモデルを過大評価しやすいため、適切な指標として機能させることが困難でした。そこでimbalancedデータに強い指標をCVの指標として採用しました。
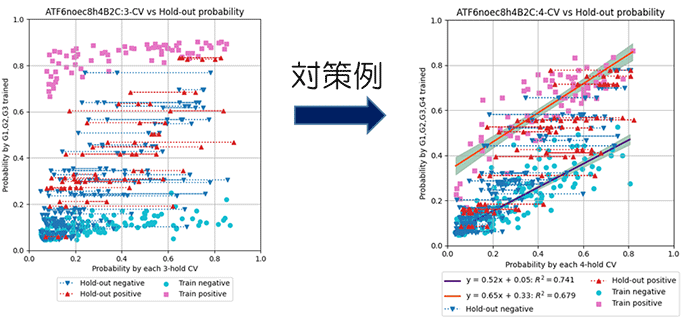
- 予測確率を活用したoverfitting対策
- CV時に単純に指標値のみでハイパーパラメーターを選定するとCV評価ごとoverfittingしたモデルが含まれていました。その対策としてCV時(CV分割された一部のトレーニングデータで学習)とhold-out評価時(全トレーニングデータデータで学習)のprobabilityの相関をチェックし、著しく相関がないモデルのハイパーパラメーターは指標値が高くても採用しないようにしました。
- 特徴量重要度に基づく記述子選択
- 構造活性相関のモデルでは入力の記述子数がデータ数に対して多過ぎることがあります。そこで次の記述子の絞り込みを実施しました。決定木系のアルゴリズムを用いていたため、CV探索による1次スクリーニングを行い、上位のモデルに対して記述子の重要度(特徴量重要度)を計算しました。算出した特徴量重要度を指標とした記述子の重要度ランキングを作成し、2次スクリーニングCV探索では記述子の重要度ランキング順に記述子を選択する個数をハイパーパラメーターに追加して探索しました。
- Multiple partitionsを用いたhold-out評価
- CV時の上位ハイパーパラメーターセットから最終的なハイパーパラメーターの選定する際にhold-outした1データセットを利用して評価すべきなのかは、データセットが小さい場合に揺らぎが大きいために判断が難しいことがあります。ここではCV実施時のデータセットとhold-outしたデータセットの他にデータ分割を何度か変えて複数のトレーニングデータとhold-outデータセットを作成し、既に得られているハイパーパラメーターでそれぞれのhold-outデータにおける評価指標を求め、この中央値を最終的な評価指標としました。なお、データセットの分割では目的変数の値で予め層化しておき、各層からランダムに抽出しました。そのため分割したデータ間における評価指標の揺らぎは比較的小さいことが期待されますが、いわゆるleakバイアスがあることには注意が必要です。
上記の4つの対策を組み込んだパイプラインを作成し、自動的に40種類のストレス応答パラメーターに対する予測モデルを構築しました。ただし、これらの対策は必ずしも他のデータに対しても汎用的に機能するわけではありません。個々のデータにあった対策を探索し、実行する必要があります。弊社では上記のような課題に対してもソリューションの開発サービスを提供します。