
概要
自由記述回答を含むアンケートやSNSを含むソーシャルメディア投稿文に代表される大量のテキストデータに対して、AI・データサイエンスの知見をもとに分析・可視化を実施し、意見を集約・抽出することで、お客さまの意思決定・課題解決を支援いたします。
テキストデータ分析・可視化
大量のテキストデータに対して、単語の頻度、単語同士の関係性、属性と文章の関係性などに基づいた可視化を行うことで、文章内の重要な意見の集約・抽出を効率的・客観的に行うことが可能になります。
テキストデータを分析・可視化する際、特に重要なことは、目的に応じた前処理を行うことです。適切な前処理を行わないと、思うような結果が得られない可能性があります。代表的な前処理には、①適切な単語の分割、②分割した単語の正規化や表現の統一、③不要な単語の削除、などがあります。
- ① 日本語のように単語ごとの区切りが不明瞭な言語での単語の分割では、単語情報を持った辞書データが必要になります。複合名詞や特定の分野における固有名詞での分割が必要な場合、お手持ちのデータや目的に応じて単語を辞書登録することで、単語の分割を調整することができます。
- ② 自由記述回答を含むアンケートやSNSを含むソーシャルメディア投稿文は、記述した個人ごとに表記ブレや誤字などが多く含まれているため、適切に分析するためには表現の統一などの正規化が必要となります。固有名詞や英数字を含む単語の表記ブレ、若者言葉、俗語など対象となる単語が多い上、実際にデータを見て対応する必要があるため、特に困難な作業になります。
- ③ 分析や可視化を行う上でノイズとなるような単語も多く存在するため、予め削除する単語を決めておく必要があります。日本語における助詞や助動詞、擬音・擬態語をはじめ、特定の分野や目的に応じて不要な単語の選定が必要になります。
サービス内容
テキストデータをお持ちのお客さまに対し、データの前処理やテキストデータの分析・分類、効果的な可視化など、お客さまがお持ちのデータや課題に合わせたコンサルティングや技術開発等をとおして、意見や課題を抽出する、ポジティブ・ネガティブ判定を行うなど、様々なサービスを提供いたします。
適用例
|
|
サービスメニュー
|
|
適用例
アンケートデータ分析支援
ここでは、2016年の参議院選挙に関するアンケート*1における、サンプル数995サンプル(内訳20代以下・30代・40代・50代・60代以上各200人から無回答5サンプルを除く)の選挙に行く/行かない理由に関する自由記述回答を分析・可視化した結果を一例としてご紹介いたします。ここで紹介する手法の他にも、トピック分析やトレンド解析のような手法、複数手法の組み合わせ、お客さまがお持ちのデータや目的に合わせたチューニング等についてもご提供も可能です。
データの前処理
本事例においては、①「期日前投票」など複合名詞の辞書登録、②「一票」「1票」などの表現の統一、③「投票」「選挙」のようにアンケートの特性上頻出する単語の削除、などを行いました。特に③で対象となる単語は、年齢や性別に関係なく多数出現するため、削除しておかないと後述する分析・可視化に強く影響を与え、不適切な解釈を導く可能性もあります。
出現頻度ヒストグラム
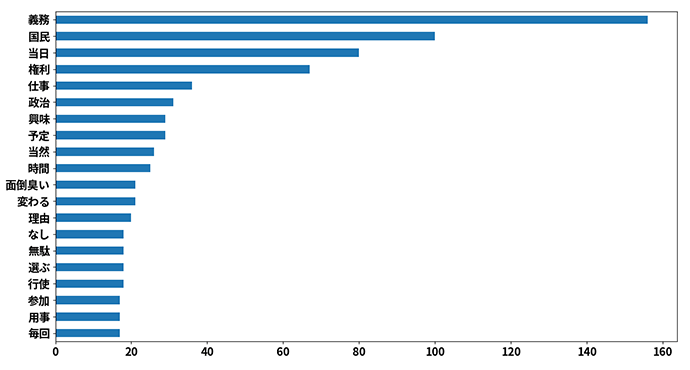
出現頻度ヒストグラムは、自由記述回答に含まれる単語を出現頻度順に並べたグラフです。図1は、縦軸を出現頻度の多い上位20単語、横軸を出現頻度としてプロットした例です。上位単語から、選挙に行く理由としては、「国民」の「義務」あるいは「権利」であるから、行かない理由としては、「仕事」や「予定」があるから、「興味」がないから、「面倒」だから、といった理由が並んでいることが読み取れます。
図1 ヒストグラム例
ワードクラウド
ワードクラウドは、自由記述回答に含まれる単語を出現頻度順に大きくプロットした図です。データ内で出現頻度の高い単語を視覚的に確認できるほか、色に情報を持たせることも出来ます。例えば、図2は、各単語のポジティブ・ネガティブ情報*2を基にポジティブなものを黄色、ネガティブなものを紫色、それ以外を緑色として色分けしています。「権利」、「期待」などのポジティブな単語が見られる一方、「無駄」や「面倒」といったネガティブな単語も散見されます。ポジティブ・ネガティブといった極性情報を独自に設定することによって、より詳細に分類したり、連続的に変化させたりすることも可能です。
図2 ワードクラウド例

共起ネットワーク
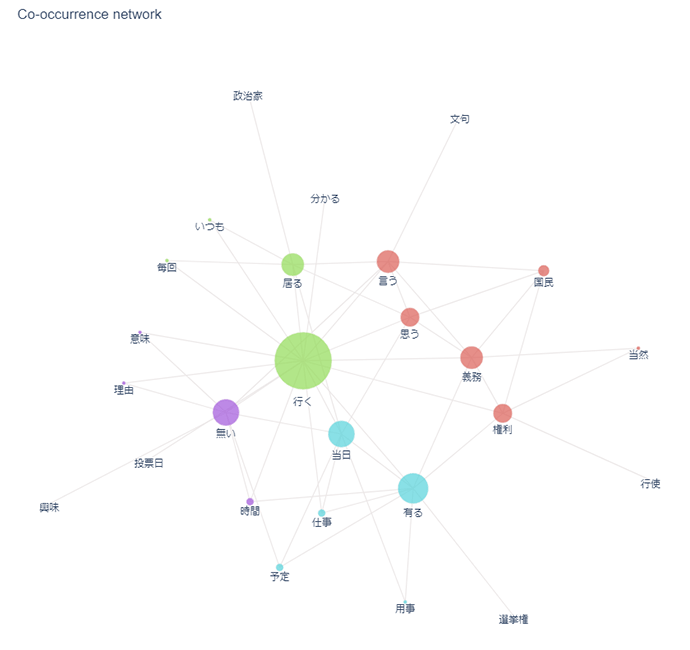
共起ネットワークは、自由記述回答に含まれる単語のうち、同じ文章内で出現した単語同士を結び、単語間の共起関係を表現した図です。共起関係は単語動詞の結び付きの強さや単語が文章中の指定した範囲内で同時に出現する頻度を表します。図3では、単語に対応する点(ノード)の大きさで共起する単語の数を、ノード間を結ぶ線(エッジ)で単語間の結びつきを表しており、ノードの関係の強いグループごとに色分けして分類しています。赤色ノードのグループは「国民」の「義務」あるいは「権利」だから投票に行く意見を示しており、水色ノードのグループは「当日」に「仕事」あるいは「予定」「用事」が「有る」から投票に行かない意見を示していることが読み取れます。他にも紫色ノードのグループからは「時間」や「興味」、「意味」が「無い」という意見や、緑色ノードのグループからは投票に「いつも」「行く」、「毎回」「行く」といった意見が読み取れます。
図3 共起ネットワーク例
コレスポンデンス分析
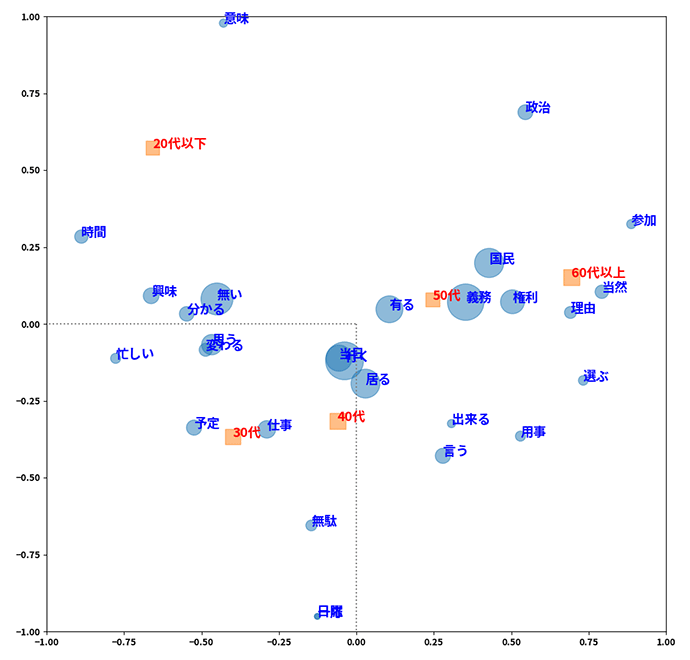
コレスポンデンス分析は、クロス集計結果を散布図にした図で、視覚的に項目間の関係性を確認できる特徴があります。図4は、自由記述回答欄の頻出単語と年齢層をクロス集計し、その関係性をプロットした例です。「20代以下」付近を見ることで、「面倒」である、「意味」や「時間」、「興味」が「無い」といった意見が20代以下に多いことが読み取れます。同様に、30代、40代には、「仕事」や「予定」で「忙しい」、投票しても「無駄」といった意見が、50代、60代には、投票に行くことは「義務」や「権利」であり、「当然」だという意見が多いという傾向が読み取れます。
図4 コレスポンデンス分析例
パラレルセット
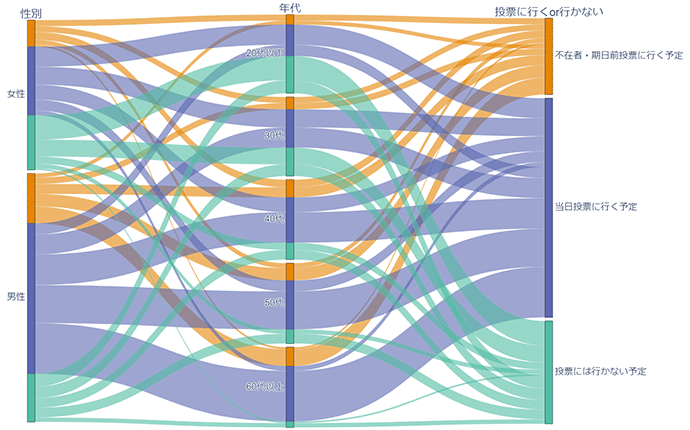
最後に、テキストデータの分析ではありませんが、性別や年代のような属性値を複数含むデータに対して、属性間の関連性を把握するのに有効なパラレルセット(平行座標プロット)をご紹介します。図5は、性別・年代・投票に行くかどうかの選択式回答をプロットした例です。全体の1/4ほどが「投票には行かない」(右軸緑)と考えており、男女の差はない(左軸緑)。一方で、「投票に行く/いかない」は年齢層により差異が大きくなっている(中央軸緑、若年層ほど緑の割合が多い)といったことが読み取れます。
図5 パラレルセット例
参考文献・データ
- *1) 「参議院選挙に関するアンケート」(資料JP https://siryou.jp/sales_material_detail/7523、株式会社クリエイティブジャパン調べ)
- *2) 小林のぞみ,乾健太郎,松本裕治,立石健二,福島俊一. 意見抽出のための評価表現の収集. 自然言語処理,Vol.12, No.3, pp.203-222, 2005. / Nozomi Kobayashi, Kentaro Inui, Yuji Matsumoto, Kenji Tateishi. Collecting Evaluative Expressions for Opinion Extraction, Journal of Natural Language Processing 12(3), 203-222, 2005.
| キーワード | アンケート, 自由記述, テキスト解析, テキスト分析, ソーシャルネットワーク, SNS, 自然言語処理(NLP), 形態素解析, 出現頻度, ヒストグラム, ワードクラウド, 共起ネットワーク, コレスポンデンス分析, クロス集計, パラレルセット, 平行座標プロット, MeCab, Sudachi, GiNZA, Plotly, 可視化, Python, JavaScript |
|---|