生命情報データの予測モデル構築
AI(機械学習・Deep Learning)モデル構築
近年、ビッグデータと呼ばれる大規模データの解析のために、AI(機械学習、Deep Learning)モデルが使用されるケースが増えてきています。AIモデルを用いることで従来手法の精度を大幅に塗り替える解析結果も報告されており*1、AIモデルを用いた解析がますます発展していくことが予想されます。
しかし、AIモデルを適切に用いるためには、データの量や性質によって適切な手法を選択する必要があります。また学習を成功させるためには、AIモデルに応じて適切な前処理も必要になります。弊社のソリューションではこれらの開発支援を一貫して行い、AIモデルの導入支援を行います。
AI(機械学習・Deep Learning)ソリューション
ソリューションの概要
AI(機械学習・Deep Learning)モデルは様々な領域で使用されており、弊社は生命情報解析分野においてもビッグデータを元にしたAIモデル構築サービスやコンサルテーションサービスを提供いたします(弊社が提供するその他のAIモデルに関するソリューションはAI(人工知能)・機械学習の技術開発・コンサルティングから確認頂けます)。
適切に学習したAIモデルを使用することで、これまでのルールベースでは気づくことができなかったデータの特徴な構造を自動で抽出し、高精度な結果を算出できることがあります。特にゲノム研究は様々なビッグデータを利用する研究領域であるため、AIモデルを用いた開発は有効であり、さらなる発展が期待されています。
しかしその一方で、どのようなAIモデルをどのような設定で使用するかは研究者の経験と知見に依存しています。そのため従来の研究と同様、様々な試行錯誤が必要となってきます。弊社のAIモデル構築支援ではデータの前処理からモデルの選定、学習支援など、下記に示すソリューションを提供いたします
- データの前処理
- AIモデルの学習、構築支援
- 学習済みモデルの評価、各種チューニング
データの前処理
教師データに偏りやノイズが多い場合、正常に学習が進まない可能性があります。データ数も学習の成否に関わりますが、用いるデータの質そのものも大きな影響を与えることがしばしばあります。本ソリューションでは、各種統計処理からデータの持つ性質を調査し、生命情報データ特有の事情を加味した前処理を行います。
またAIモデルの入力情報への成形も適切に行う必要があります。例えば塩基配列は一次元のA、C、G、Tの列で、このような一次元配列の場合はone-hotベクトルと呼ばれるベクトル量として変換することが一般的です。一方で次世代シーケンサーデータの変異callフィルターモデルの構築等では塩基配列を画像データとして扱う場合もあります。
機械学習・Deep Learningモデルの学習、構築の支援
AIモデルの目的用途に合わせて、モデル構造(畳み込みニューラルネットワーク、リカレントニューラルネットワークなど)の選定を弊社が支援いたします。また様々なパラメーターの調整も弊社が支援し、高い精度のAIモデルの導入に向けた支援を提供いたします。
これまで弊社で提供してきたAIモデル導入の経験をもとに、お客さまの課題を理解させていただいたうえでAIモデル構築の支援サービスを提供いたします。下図に示すように、課題の精査、学習モデルの選定、データの前処理、学習・評価、ハイパーパラメーターの選定、ならびに学習結果の解釈までを支援いたします。

実例紹介
国立がん研究センターとの共同研究として取り組んだSpliceAIモデルを用いたエンハンサー領域予測のための学習を実施しました。
使用ライブラリについて
オリジナルのSpliceAIの学習コードはPython2とTensorFlow1が用いられていましたが、本例ではPython3、TensorFlow2を用いています。これらのライブラリは開発環境に合わせて柔軟に対応することが可能です。また本例では仮想化技術であるDockerを用いて開発環境を構築しており、作成するDockerイメージを配布することで、煩雑なライブラリの導入などを行わずAIモデルを使用していただくことが可能です。
SpliceAIについて
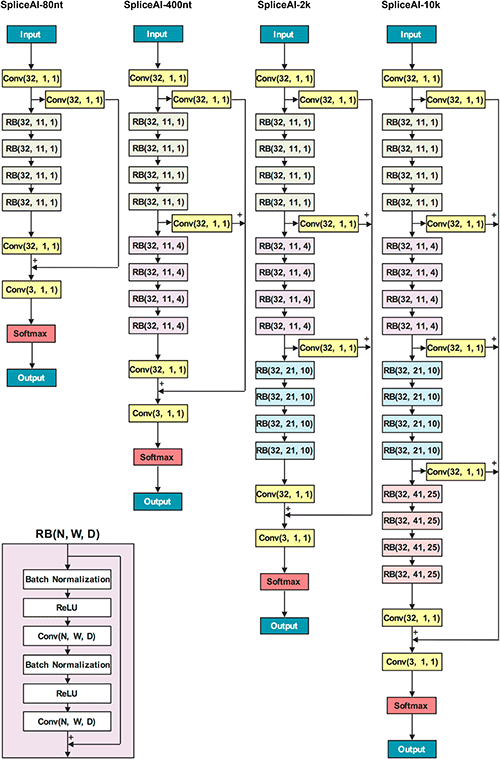
SpliceAI*1は2019年に発表された長距離の塩基配列の影響を組み込んだモデルであり、スプライシングのdonor及びacceptorの位置予測を行うことができます。これまでのスプライシングサイト予測ツールの性能を大幅に超えることに成功し、個人ごとの変異によるスプライシングの変化も予測することができます。SpliceAIモデルは塩基配列をone-hotベクトル化した情報を入力として受け取り、図1に示したように1次元の畳み込みニューラルネットワークを何層にも重ねた構造を取っています。また、より深層化するためにResidual Networkの構造を採用しており、これまで画像認識タスクで発展してきた技法を効果的に用いたネットワーク構造となっています。
図1 SpliceAIモデル*2
エンハンサー領域予測への転用
これまでエンハンサー領域予測を行うツールは数多く発表されてきましたが、個人ごとの多型による影響を予測するアノテーションツールとしての開発は進んでいませんでした(弊社調べ)。
そのため弊社は、エンハンサー領域予測へSpliceAIモデルを転用した実験を行いました。SpliceAIモデルでは長距離の塩基配列の情報を集約することができるため、エンハンサー領域の予測にも流用できると期待されました。
使用したデータと前処理について
本実験ではFANTOM5*2のデータを用いました。FANTOM5のアノテーション結果では様々な情報が利用可能であり、これらの相関関係などを確認し、ネットワークや計算機環境に合わせた前処理を実施いたしました。また本試行の実施のため、各種のソフトウェアの調整も行いました。
学習結果
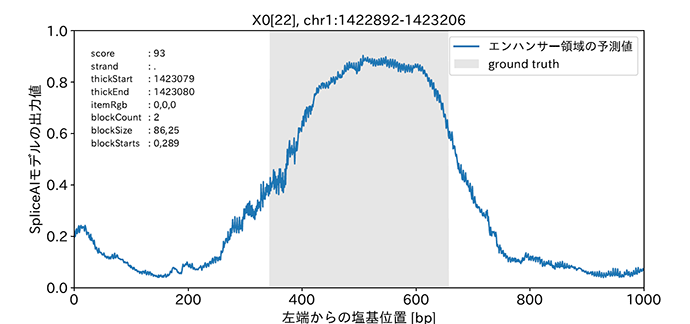
SpliceAIモデルを使用しエンハンサー領域を学習させたモデルを用いて、評価データに対して予測した結果を図2に示しました。横軸に塩基配列(位置)、縦軸にエンハンサー領域である予測値(その塩基がエンハンサー領域に含まれるかどうか)としています。灰色の背景部分はFANTOM5のアノテーション領域であり、青線が予測結果です。アノテーションの領域に対して高い確率値の分布を示しており、学習が一定の精度で成功していることが分かります。ただし評価データによっては予測機構がうまく働いていない場合もあり、これはSpliceAIモデルの流用による限界なのかデータの表現が不適切なのか等が今後の研究課題となりました。
図2 エンハンサー領域の予測例
補足情報
本例において初期値によって学習が進まない現象が生じたため、畳み込みニューラルネットワークパラメーターの初期値分布を洗い出しました。SpliceAIでは初期値を与える一様乱数の範囲によって、学習が収束するかどうかが左右されていました。この例のように、AIモデルによる研究は絶妙なバランスを保ったパラメーター群を探索できるかどうかが成否の重要な鍵を握っています。
参考文献リスト
- *1Predicting Splicing from Primary Sequence with Deep Learning
- *2Maria Dalby, Sarah Rennie, & Robin Andersson. (2017). FANTOM5 transcribed enhancers in hg38 [Data set]. Zenodo.
http://doi.org/10.5281/zenodo.556775