News & Blog
MCP×エージェントによるデータ活用の高度化


概要
大規模言語モデル(LLM)は、自然言語による質問応答や文章生成において大きな可能性を持ちながらも、現時点の情報を取得するには、外部データとの連携を要します。その課題を解決する手法としてOpenAIのFunction
Callingが登場しましたが、再利用性には限界がありました。
この課題に対し、Anthropicが提唱したModel Context
Protocol(MCP)[1]は、LLMと外部サービス・データとのインターフェースを標準化し、再利用可能な形での連携を実現するものです。MCPの導入により、エージェントが自律的に外部情報を活用し、より高度なタスクを遂行できるようになっています。
本稿では、MCPとエージェントの連携による、社内情報資産の有効活用への新たな可能性について、AI Powerhouseの研究例も交えて解説します。
1. LLMの外部情報利用
近年、LLM技術は飛躍的に発展し、様々なユースケースで応用されています。ただ、LLMに、外部情報にアクセスするツールを渡さない限り、外部情報を参照しながら回答することはできません。
この課題を解決するため、OpenAI社はFunction
Callingという手法を提案しました。これは、あらかじめ「関数の定義」をLLMに与えることで、LLMがその関数を呼び出すための構造化された情報を出力、その出力結果により Function
Callingを構成するツール類が動作することで、LLMが外部にアクセスできるようにするというものです。
しかしながら、Function
Callingはアプリケーション内に外部サービスを利用するコードを組み込む必要があるため、再利用性に乏しいという課題があります。また、OpenAI社独自の仕様であるため、他社製のLLMにそのまま適用することは困難でした。
2. MCP(Model Context Protocol)の登場
Anthropicが2024年11月に発表したMCPは、急速な成長を遂げ、サードパーティのマーケットプレイスで16000以上のMCPサーバが収集[2]されるなど、さまざまな業界で革新的な活用事例が生まれています。これは、MCPが、LLMと外部データ・ツールの間をつなぐプロトコルとして、オープン標準だからです。
MCPは、外部サービスを利用する際にクライアントとサーバを分離する設計思想に基づいており、アプリケーション側ではMCPクライアントを、外部サービス側ではMCPサーバをそれぞれ定義するという仕組みです。これにより、以下のような三つの主要な利点が得られます。
■ 標準化の利点
MCPは統一されたインターフェースを提供することで、開発者が一度の実装で複数のサービスと連携できるようになります。
■ 拡張性の実現
新たなツールやサービスがMCPに対応すれば、それを既存のAIワークフローに容易に組み込むことが可能です。プラグインのような形式で機能を追加できます。
■ セキュリティの確保
MCPは認証やアクセス制御を標準化し、企業レベルでの安全な外部リソースへのアクセスを実現します。
3. MCP×エージェントの応用
MCP技術により、LLMがスケーラブルに外部サービスへアクセスできるようになったことで、自律的な情報収集やタスク遂行がさらに容易になりました。ここでは、エンジニアがよく利用するサービスにおけるMCPの具体例を紹介します。
■ Slack MCP
現代の企業コミュニケーションでは、会議の議事録作成や進捗報告、チャットの会話から重要情報を抽出する作業が重要である一方、非常に手間がかかります。Slack MCP[3]を用いれば、メモや文字起こしの共有、チャット履歴の読み込みによる決定事項・アクションアイテムの構造化、さらにはプロジェクト管理ツールとの自動連携やチケットの自動生成が可能となります。
■ Perplexity/Notion MCP
従来の検索システムでは、社内外の最新情報を統合するのは困難でした。Perplexity MCP[4]はリアルタイムのWeb検索機能を提供し、Notion MCP[5]は組織内ドキュメントの検索を可能にします。これらを組み合わせることで、社内外の知識を包括的に統合できます。
■ Linear/Jira MCP
ソフトウェア開発において、プロジェクト管理は開発者が創造的な作業に割り当てる時間を圧迫する大きな要因です。Linear/Jira MCP[6][7]はこの問題に対する抜本的な解決策を提供します。会議音声の解析により、言及された課題や改善案を自動でチケット化したり、プルリクエストのレビューコメントから追加タスクや技術的負債の管理チケットを自動生成したりすることが可能です。
4. コード開発・ドキュメント作成への応用
AI Powerhouseでは、MCPとエージェントの連携によるシステム開発への応用に関する研究を進めています。本節では、コード開発とドキュメント自動作成における具体的な応用例を紹介します。
(1)コード開発への応用
開発者は類似プロジェクトを探す際、手動でリポジトリを検索し、関連ファイルを一つひとつ確認しなければなりませんでした。今回、我々は、過去のシステム開発の知見をGitBucketに蓄積し、GitBucket
MCPを構築することで、エージェントが過去のプロジェクトを参照しながらコードを生成できることを確認しています。
GitBucket
MCPはStreamable-HTTP[8]を用いて実装されており、リアルタイムでのリポジトリ情報取得や階層的な探索が可能です。今後、GitHubやGitLabへの移行に際しても、同様のシステムを構築できます。さらに、GitHub
Actionsとの連携により、mainブランチへのマージ時に検索用の要約やタグを自動生成する仕組みを整えれば、最新情報に基づいた検索環境を構築することができます。
「フィードバック機能を搭載したシンプルなStreamlitアプリを作成してください。過去事例で類似のものを作成しているので、社内リポジトリを参照してください」という指示に対して、GitBucket
MCP×エージェント系がどのように動作し、どのようなアプリケーションを生成したかを以下に示します。

図1-1 エージェントの動作フロー
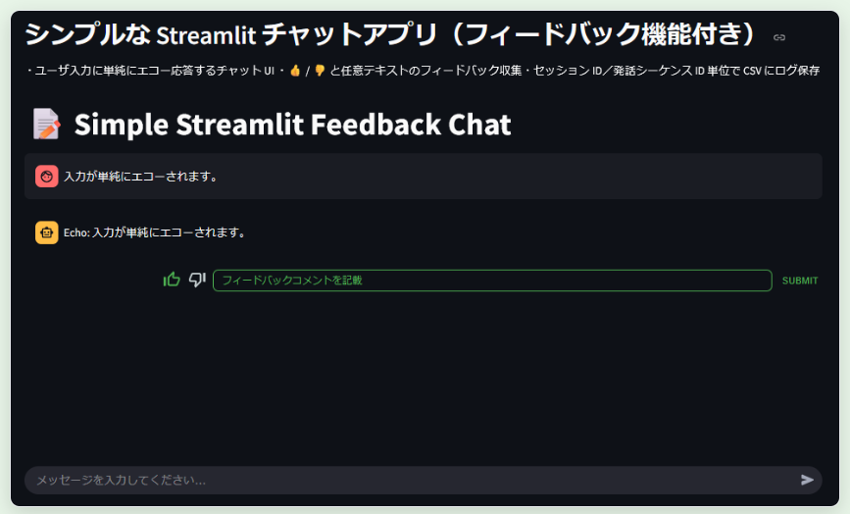
図1-2 生成されたアプリケーション例
(2)ドキュメント作成の自動化
技術ドキュメントの作成は、高い正確性と網羅性が求められる一方で、非常に多くの時間と労力を要する作業です。特に、複雑なセットアップ手順や技術仕様の記述には、コードベースに対する深い理解と、それを明確に伝える文章力の両方が不可欠です。
前節で紹介したGitBucket MCPに加え、FileSystem
MCP(ファイルの作成・編集が可能なMCP)を組み合わせることで、ドキュメントのたたき台を自動生成することができます。たとえば、「リポジトリ○○でモデルを学習する手順を調査し、手順書.mdとして格納してください」といった指示に対して、以下のような動作フローを実現できました。

図2-1 エージェントの動作フロー
このアプローチを活用することで、長期にわたり開発が続いているプロジェクトにおいて、READMEと実態との乖離を是正することが可能です。READMEの自動的な更新により、プロジェクトの理解を促進し、新規メンバーのオンボーディング効率の向上も期待できます。さらに、GitBucketリポジトリを分析させることで、各分野の技術エキスパートを可視化する、いわゆる「ナレッジマッピング」を自動生成することも可能となるでしょう。
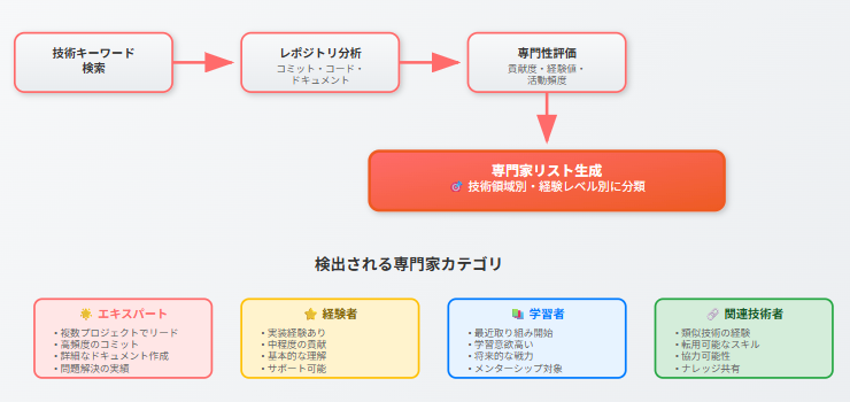
図2-2 ナレッジマッピング
5. まとめ
MCPは、LLMの能力を実世界に拡張するための強力な基盤技術です。標準化されたインターフェースにより、複数の外部ツールとの柔軟な連携が可能となり、開発者が容易にデータ活用を進められる環境が整いました。
今後、さらに多様なMCPサーバが登場し、社内外のデータとAIの接続性が一層高まることで、企業の知識資産の活用は新たな段階に進むことが期待されます。MCPとエージェントの連携によるAI活用は、単なる業務効率化にとどまらず、知識の蓄積・活用・継承のあり方を大きく変えていく可能性を秘めています。
私たちは、今後も、さまざまな分野で新たな価値を創出するための取り組みを推進してまいります。本稿で取り上げたMCP技術、エージェント活用に関するご相談がありましたら、是非お気軽にお問合せください。
参考文献
[1]: Introduction - Model Context Protocol
[2]: https://mcp.so/
[3]: @modelcontextprotocol/server-slack - npm
[4]: GitHub - ppl-ai/modelcontextprotocol: A Model Context Protocol Server
connector for Perplexity API, to enable web search without leaving the MCP
ecosystem.
[5]: Notion MCP – Connect
Notion to your favorite AI tools
[6]: Linear MCP
server – Changelog
[7]: アトラシアン、リモートMCPサーバーを発表 | Atlassian Japan 公式ブログ | アトラシアン株式会社
[8]: Transports - Model Context Protocol