
情報通信研究部 チーフコンサルタント 山泉 貴之
寄り道検索と関連語辞書
(1)調べもの検索と同義語・類義語辞書の関係からの類推
調べもの検索の性能向上のためには同義語・類義語辞書が不可欠であるように、寄り道検索の実現のためにも、独自の「辞書、または類似のソフトウェアまたはシステム」の存在が不可欠であると考えられる。
そこで、単語または単語の組について「単語の意味が同一、または似通っているかどうかの判断」を必須としない関連語の組を生成し、その集合体をもって辞書を生成する手法、すなわち関連語辞書を生成する手法について検討する。 関連語辞書は収録の対象となる単語の組を、関連語の抽出の対象となる文書群における単語の組の出現数がある閾値以上であるか否かによってのみ決定する。これにより、「単語の意味が同一、または似通っているかどうかの判断」が必須でなくなるため、その判断のために必要な人的コストを削減することができる。
本稿で検討する関連語辞書を構成する単語の組に類似した概念として、指定された語に対して次の単語の候補としてユーザに提示するための単語の組を集めた辞書があり、はてなキーワード連想語API(5)やGoogleサジェスト(6)等がそれぞれ独自に辞書を構築している。これらの辞書は、検索語として得られた単語どうしのみを直接用いて「単語の意味が同一、または似通っているかどうかの判断」を行っていないため、関連語辞書に分類できる。しかし、これらの辞書はユーザが検索を行った際に指定した検索語とともに検索語として指定した順序についての情報等を蓄積及び利用することで辞書を構成する単語の組を抽出しているため、ユーザがほぼ同時に思いついた単語どうしが単語の組として抽出されやすい。また、より一般的な文書等から単語の組を自動的に抽出する手法を採っていないことにも留意する必要がある。
ここまでの考察をもとに、同義語・類義語辞書及び関連語辞書と想定される用途の対応を図表3に示す。
図表3 同義語・類義語辞書及び関連語辞書と想定される用途の対応
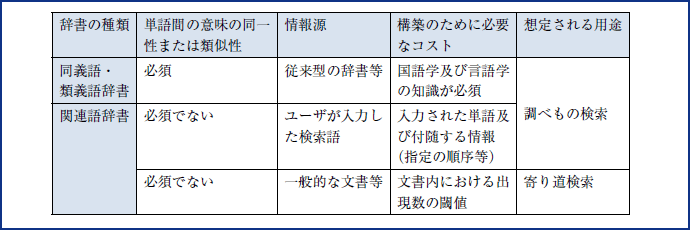
(資料)みずほ情報総研作成
(2)寄り道検索の有効性と調べもの検索との関係
同義語・類義語辞書を用いた従来型の検索手法である調べもの検索はユーザの検索についてのニーズが顕在化しているときに有効である。一方、関連語辞書を用いた新しい検索手法である寄り道検索はユーザの潜在的なニーズを顕在化させるのに有効である。
つまり、ユーザのニーズが定まっていない段階で検索する上では、同義語・類義語辞書で範囲を狭めた検索のみで必要な情報を得るよりも、関連語辞書で範囲を拡げて検索を行うことで、ユーザが「実はそれが知りたかった」情報に辿り着き易くする効果を得ることができる。
したがって、寄り道検索及び調べもの検索は互いに排他的なものではなく、ユーザにとってのニーズの顕在度に応じて2つの検索手法を補完的に使い分けることにより、ユーザにとってより最適な検索結果を得ることができると考えられる。
関連語辞書の生成
(1)関連語辞書を生成するための技術的な課題
次に、寄り道検索の実現に必要な関連語辞書の生成手法について検討する。
関連語辞書を生成するためには以下の技術的な課題が存在する。
[1] 関連語辞書に収録するための単語の組を集計するための効率の良いメモリの利用法及び処理方法の確立
関連語辞書は2個の単語の間の関係の強さを評価し、関連性が強いものを抽出することで生成できる。関係の強さを評価するためには、文、文書または文書群(以下、単に「文書等」と書く。)に現れる文字を単語に分解し、その中から任意の2つの単語の組及びその関係の強さを表す量の三つ組のデータを抽出して、その途中経過または結果を配列として保持する必要がある。
2つの単語の組み合わせの数は文書等に現れる単語の数の2乗に比例して増加することから、それらの組み合わせをすべて格納することとした場合、メモリの使用量も単語の数の2乗に比例して増加する。したがって、メモリの使用量を抑制しつつ、2つの単語の関係の強さを評価する手法を確立することを技術的な課題として挙げることができる。
[2] 2つの単語の関係の強さを求めるための評価手法の選択
関連語辞書の生成にあたっては2つの単語の関係の強さ同士を比較する適切な手法を選択する必要がある。2つの単語の関係の強さ及びその比較のための手法としては以下の手法がすでに提案されている。
- 共起分析:単語の組が同時に出現したかどうか、また出現した場合にはその出現状況(単語の組の出現回数や連続して出現したか否か等)をもとに単語の組についての関連度の強さなどの分析を行う手法である。
- Word2Vec(7), Glove(8), fastText(9):ニューラルネットワークを利用して単語に対応するベクトル値を求め、そのベクトル値の近さで関係の強さを求める手法である。
- Poincare Embeddings(ポアンカレ空間への埋め込み)(10):単語をユークリッド空間におけるベクトル値へ変換するかわりに、双曲空間(Hyperbolic Space)におけるベクトル値へ変換する(埋め込み)することでベクトルの次元数を削減する手法である。
関連語辞書を自動的に生成するにあたってはコンピュータのメモリ資源の効率的な利用の観点から2つの単語の関係の強さを表すパラメータをできるだけ少ない次元数で保持することと、関係の強さの計算及び比較についてもできるだけ単純な計算式で実行できることが望ましい。
本稿では、上記の手法のうち2つの単語の関係の強さを表すパラメータ(=「単語の組の出現回数(または出現率)」)を最も少ない次元数で保持できる共起分析を用いて単語間の関係の強さを求める。2つの単語の関係の強さの比較は単語の組の出現回数(または出現率)を比較するだけで行うことができる。
(2)関連語辞書の自動生成手法とその生成例
関連語辞書生成のためのメモリの効率のよい利用法を探るため、弊社において以下の手順により関連語辞書を自動的に生成する手法を考案し、関連語辞書の生成を試みた。
- [1]大量の文書群(以下、「原文書群」と記す。)から一部の文書群(以下、「サンプリング文書群」と記す。)をランダムに抽出し、共起分析器を用いて共起分析を行う。具体的には、1個の文書内で2つの単語の組(以下、「単語組」と記す。)が出現する文書数を集計し、文書数の分布を求める。
- [2]文書数の分布、原文書群の文書数及びサンプリング文書群に属する文書数(以下、「サンプリング文書数」と記す。)から関連語辞書に収録可能な出現率の下限値(11)を決定する。
- [3]原文書群の文書群を複数の文書群(以下、「サブ文書群」と記す。)に分割する。なお、サブ文書群の個数は原文書群の文書数をサンプリング文書数で割った値をもとに決定する。
- [4]手順[3]で作成したサブ文書群ごとに手順[1]と同様の方法で単語組のサブ文書群における出現率を求め、データ分析器を用いて手順[2]で決定した関連語辞書に収録可能な出現率の下限値以上の単語の組のみを抽出する。
- [5]手順[4]でサブ文書群ごとに抽出した単語組の出現数を集計し、関連語辞書を得る。関連語辞書は無向グラフの形式で表現できるので、グラフ生成器を用いてその内容を確認できる。
図表4は上記の手順[1]~[5]の手法を図解したものである。
図表4 関連語辞書の生成例
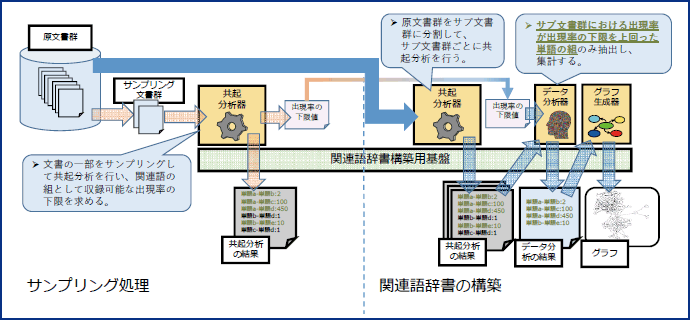
(資料)みずほ情報総研作成
本レポートは当部の取引先配布資料として作成しております。本稿におけるありうる誤りはすべて筆者個人に属します。
レポートに掲載されているあらゆる内容の無断転載・複製を禁じます。全ての内容は日本の著作権法及び国際条約により保護されています。