
情報通信研究部 チーフコンサルタント 山泉 貴之
関連語辞書の生成結果例と応用例
4節で示した手法により関連語辞書を生成すると、辞書内における単語間の関係性は無向グラフや隣接行列(12)等で表現できる。日本語版Wikipedia(13)を原文書群として用いて生成した関連語辞書内において、関連性が特に強いと判定できる単語間の関係について無向グラフを用いて描いたものを図表5に示す。
次に、原文書群自体を交換することで専門性を持った関連語辞書が作成できるかどうかについての初歩的な検討を行うために、日本語版Wikipedia から「野菜」のカテゴリに属する文書を抽出して原文書群とし、4節で記述した手法で3,251個の単語及びそれらの単語間の関係から構成される関連語辞書を生成した。さらに、生成した関連語辞書を用いて、関連語と判定された単語をどのように辿ることができるかを確認するため、最初の検索語として「キャベツ」を指定した場合に辿ることのできる単語の例を有向グラフで描いたものを図表6に示す。図表6より、「キャベツ」を起点に「ズッキーニ」→「夏野菜」→「ナス」→「作品」という経路や「食感」→「特産」→「文化」→「キャラクタ」という経路での関連語の検索ができることが確認できる。
図表5 日本語版Wikipediaを原文書群として用いた場合の関連語辞書の生成結果の抽出例
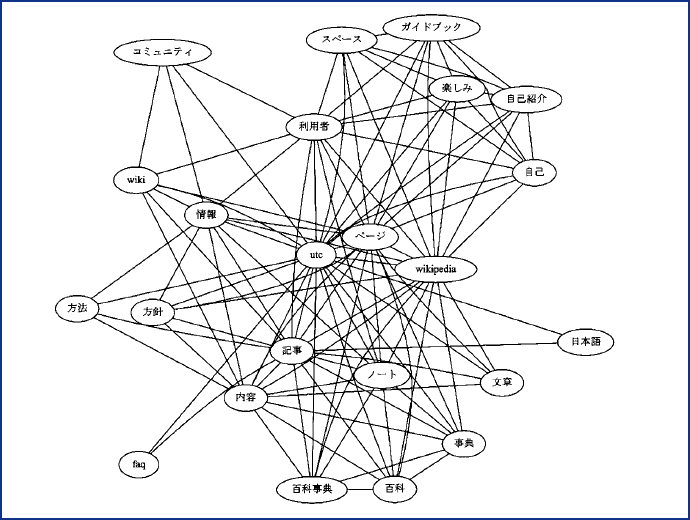
(資料)みずほ情報総研作成
図表6 関連語辞書により辿ることのできる関連語の経路例
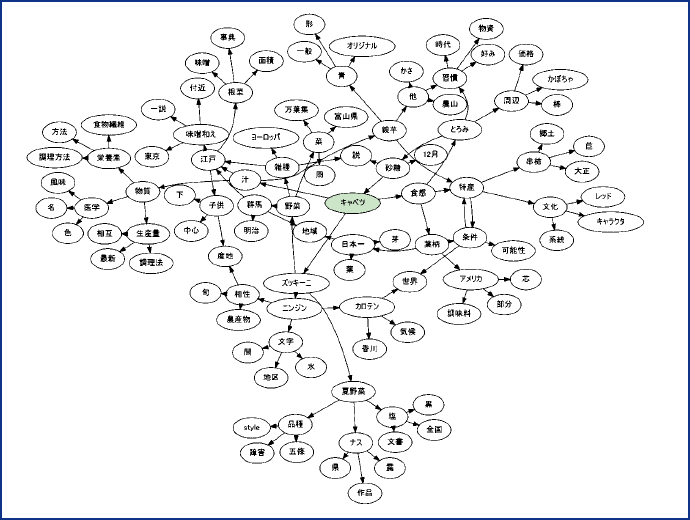
(資料)みずほ情報総研作成
今後の展望及び課題
本稿で検討した関連語辞書の生成手法によって生成した関連語辞書は、文書群の種類を変えることにより、元の文書群が持っていた書き癖や専門性等を反映させることが可能である。また、3節で検討した通り、従来から利用されている同義語・類義語辞書及び調べもの検索との併用も可能である。
関連語辞書は書き癖や専門性等を反映させることができるという特徴を持つことから、以下のような用途例が考えられる。
- 企業内のドキュメントをコーパスとして用いてその企業が持っている専門性を反映した関連語辞書を生成し、それを利用した関連語の提示機能を情報検索システムに付加することで、企業内の異なる部門間での意思疎通の円滑化を促進する。
- E-コマースのサービスを提供しているWebサイトでは、情報検索システムに関連辞書を用いた関連語の提示機能を追加し、ユーザを寄り道検索へ誘導することで、Webサイトへの滞在時間を増大させ、サイト内の商品にできるだけ多くアクセスさせることにより、ユーザ体験の向上が期待できる。
また、本稿における考察及び検討の結果より、今後は以下の課題についての検討が必要であろう。
- 企業の内部に蓄積されている文書群を入力として関連語辞書を生成する場合、本稿において関連語辞書の生成に用いた日本語版Wikipediaと比較して、文書の長さのばらつきが大きいことが考えられる。4.(2)節で試みた手法では、メモリの使用量は文書内に現れる単語数の2乗に比例して増加するため、比較的少ない文書量でもメモリの必要量がコンピュータに搭載されているメモリ量を超えてしまい処理が難しくなることがある。そのため、メモリの使用量を抑制する手法の検討が必要である。
- 本稿では大量の文書群を対象とした辞書の生成を想定し、文書群の中からサンプリングして抽出したサブ文書群における単語の組の出現率の分布のみを用いて閾値を設定し、それを用いて関連語辞書への収録の可否を決定している。本稿で検討した関連語辞書への収録条件及び生成された関連語辞書は簡易的なものであり、収録条件及び関連語辞書に収録されている単語の組の範囲の妥当性については詳細な検討が必要である。
注
- (1)「令和元年版情報通信白書」によると、2018年のスマートフォンの世帯保有率は約8割(79.2%)であり、20代以下では(2015年時点における)インターネットの利用時間はテレビの視聴時間よりも多くなっている。
- (2)同義語は意味がほぼ同じ言葉を指し、類義語は相互に変更可能で文脈によっては代替(言い換え)が可能である語で、類語ともいう。
- (3)
- (4)
- (5)
- (6)
- (7)Word2Vec: Tomas Mikolov, Ilya Sutskever, KaiChen, Greg Corrado, and Jeffrey Dean,“Distributed Representations of Words andPhrases and their Compositional ity.”, InProceedings of NIPS, 2013.
- (8)Glove: J. Pennington, R. Socher and C. D.Manning, “Glove: Global vectors for wordrepresentation,” In Proceedings of the 2014Conference on Empirical Methods in NaturalLanguage Processing, pp. 1532?1543, 2014.
- (9)fastText: O. Levy and Y. Goldberg, 「Neural wordembedding as implicit matrix factorization,」InAdvances in Neural Information ProcessingSystems, 27, pp. 2177?2185, 2014.
- (10)Poincare Embeddings(ポアンカレ空間への埋め込み):Maximilian Nickel and Douwe Kiela, 〝PoincareEmbeddings for Learning Hierarchical Representations,〟 In Advances in neural informationprocessing systems, pp. 6338-6347, 2017.
- (11)サンプリング文書群に属する文書の数とサブ文書群(後述)に属する文書の数が一致するとは限らないため、単語組の出現回数に代えて出現率を求めている。
- (12)グラフ理論において有限グラフを表すために使われる行列である。行列の要素は頂点の対を表し、その値が0でない場合にはその頂点の対の間が辺によって直接接続されていることを示す。
- (13)日本語における大規模文書群で、かつフリーで利用可能なものが少ないため、本稿においては日本語版Wikipedia を利用して関連語辞書を生成し、それを用いた検索モデルについて検討した。
本レポートは当部の取引先配布資料として作成しております。本稿におけるありうる誤りはすべて筆者個人に属します。
レポートに掲載されているあらゆる内容の無断転載・複製を禁じます。全ての内容は日本の著作権法及び国際条約により保護されています。