技術動向レポート
データ駆動型材料開発の現在地とこれから(2/2)
サイエンスソリューション部 コンサルタント 石田 純一
3.データ駆動型分析ツール
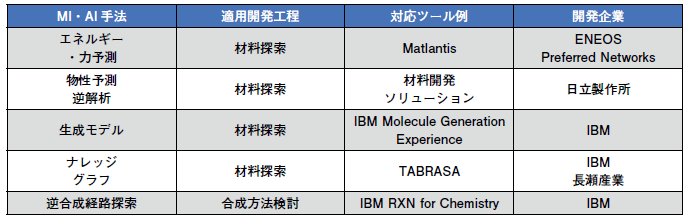
データ駆動型開発がアカデミア・民間企業各所で行われているが、一部企業においてはAIを活用した分析ツールを有償または無償で提供している(図表3)。2021年7月には、ENEOS社とPreferred Networks社が共同で開発した汎用原子レベルシミュレータMatlantisが有償クラウドサービスとして公開された*14。材料を構成する原子に働くポテンシャルエネルギーをAIによって予測することで、計算コストが高いDFT(Density Functional Theory)計算に比べ一万倍以上高速なシミュレーションを実現したとされる。従来手法に匹敵する計算精度も得られており、触媒や電池材料等の開発が大幅に効率化される可能性がある。
IBM社はAIによる物質探索の支援をサポートするため各開発工程に特化した複数のサービスを構築し、一部の機能を無償公開している*15,*16。その一つであるIBM Molecule GenerationExperience では、所望の物性を持つ材料をAIが自動作成する分子生成モデルをウェブブラウザ上で利用できる。また化学反応・逆合成経路探索ツールIBM RXN for Chemistryを用いて化合物の合成経路を確認することができる。
その他にも、ここ数年で国内外の多くの企業が自前のAIモデル開発やデータベース構築を行い、データ駆動型の材料分析ツールを提供している。ウェブブラウザ上での操作やクラウド環境での計算実行を特徴とするソフトウェアも多く、データ駆動型開発を行うためのハードルが徐々に低下している。
図表3 エネルギーマネジメント先進企業(ドイツ)
- (資料)各種情報よりみずほリサーチ&テクノロジーズ作成
4.注目技術動向
基礎研究レベルでも新たな技術開発は活発である。数多くの注目技術が存在するが、例えば2010年代後半に登場したグラフ畳み込みニューラルネットワーク(Graph Convolutional NeuralNetworks, GCNN)と呼ばれる機械学習モデルはMI手法の開発に大きなインパクトをもたらした。このモデルでは、化合物中の原子同士の結びつきをグラフ構造と見立て、グラフの頂点(原子に対応)・辺(化学結合に対応)に周辺環境を織り込んだ情報を集積し、物性予測性能を獲得している(図表4)*17。さらに近年、座標情報や並進・回転対称性といった化合物の物理的性質を学習に反映させた幾何学的深層学習が注目されており、物性予測のみならずエネルギー・力の予測でも高い性能を示している*18。このAIモデルを分子動力学計算に活用すると、計算コストのかかる第一原理計算をAIで置き換えた高速・高精度シミュレーションが実現する可能性があるため、基礎研究でありながら応用側にも近い技術として非常に興味深い。
アカデミア・材料系企業のみならず巨大IT企業も材料開発を推進している。2020年にはFacebook社とCarnegie Mellon大学が共同で開発した触媒材料に関するデータベースプロジェクトOpen Catalyst Projectが公開された*19。触媒材料の構造を入力として、原子毎の力や位置、構造のエネルギーを予測するための第一原理計算由来の膨大なデータが用意されている。2021年7月にはMicrosoft社が材料科学分野の研究機関をアムステルダムに新設し、機械学習を活用した分子シミュレーションの推進を標榜している*20。また上述のPreferred Networks社が材料・創薬分野での研究開発を進めるなど、従来はアカデミアや材料系企業の独壇場であった材料開発に国内外のIT企業が参入を進めており、今後勢力図が書き換えられる可能性がある。
5.現状の課題
現在ではデータ駆動型材料開発の実力が認められつつあるが、その活用に際してはAIそのものの性質に起因した以下のような課題が存在する。
第一に、データが少ない材料系はAIの恩恵を受けづらい。大規模系などシミュレーションによる物性予測が難しい場合や、秘密データ・実験失敗データなどオープンデータが活用しづらい場合には、少量データに基づいたモデルを構築せざるを得ず十分な精度が得られない可能性がある。
第二に、データベースや計算環境の整備に向けた設備投資や人材確保が必要となる。特に自前で第一原理計算データベースを構築する場合や、大規模データに基づく学習を行う場合にはオンプレミス・クラウドいずれの計算環境であっても相応のコストを要することになる。また、それらを維持・管理しデータを材料開発に活用できる人材がいなければ宝の持ち腐れとなるリスクがある。
第三に、AIはデータの内挿性に優れるが外挿性に欠ける。たとえば、特定の原子から構成される化合物のデータセットを用いて学習や物性予測を行った場合、それらの原子を含むテスト用化合物に対しては高い予測精度が期待できる。一方でデータセットに含まれない原子を含む化合物に対しては性能の悪化が懸念される。
6.今後の展望
第一の課題を解決するため、事前に取得可能な大規模データで学習したモデルを小規模データに転用し再学習する技術(転移学習)が採用されることがある。近年は膨大な数のパラメータから成る汎用性の高い学習済みモデルを、各ユーザーが自身の用途に合わせチューニングする流れが特に自然言語処理分野で一般化しつつある。材料科学分野でも、たとえば学習済みの力場モデルをケースごとにチューニングするなどの動きが起こる可能性は否定できない。また、データ拡張・データ生成等による精度向上技術は今後も着実に進展するものと見込まれる。
第二の課題に関しては、設備投資に先立ちデータ駆動型材料開発を推進するための効果的なITソリューションを提案できる人材の確保が重要となるだろう。そのため各研究機関における人材育成や、材料系企業と豊富な計算資源・優れたAI技術を有するIT企業との合従連衡が今後のトレンドとして加速する可能性がある。
第三の課題には、ガウス過程回帰といった誤差評価が可能な予測モデルの適用や化合物情報の追加によるデータベースの拡充が有効であると思われる。また、類似データの存在しない領域の材料探索に理論・実験・シミュレーションが威力を発揮することは、これまでの材料科学の歴史が証明している通りである。そのため、未開の材料を探索する上では従来技術とAIを高度に組み合わせた技術開発が一層重要になるだろう。
AIを用いた材料開発は基礎研究レベルでは数多くの成果を生み出しているが、実際の開発現場へ適用できる技術は決して多くはなく、今後も模索が必要であると筆者は考えている。しかしながら、世界的に競争が激化する材料開発において日本が一歩先をリードするためには、AI・データ・人材への果敢な投資と、「データ中心の材料開発」に向けた本格的な舵取りが必要になるものと思われる。
参考文献
- *1国立研究開発法人 科学技術振興機構 プレスリリース
- *2日経クロステック
- *3東北大学 プレスリリース
- *4科学技術未来戦略ワークショップ報告書 材料創成技術を革新するプロセスインフォマティクス(PDF/622KB)
- *5Materials Genome Initiative
- *6科学技術未来戦略ワークショップ報告書 材料創成技術を革新するプロセスインフォマティクス(PDF/193KB)
- *7NOMAD Centre of Excellence
- *8MARVEL
- *9情報統合型物質・材料開発イニシアティブ
- *10超最先端超高速開発基盤技術プロジェクト
- *11内閣府 戦略的イノベーション創造プログラム
- *12内閣府 マテリアル戦略
- *13グリーンイノベーション基金事業
- *14Preferred Computational Chemistry MATLANTIS
- *15IBM Molecule Generation Experience(MolGX)
- *16IBM RXN for Chemistry
- *17石田純一「結晶畳み込みニューラルネットワークによる熱膨張係数予測」, みずほリサーチ&テクノロジーズ技報、Vol1, No1(2021年)
- *18Shuaibi, Muhammed, et al. 「RotationInvariant Graph Neural Networks using SpinConvolutions」, arXiv preprint, arXiv:2106.09575(2021年)
- *19Facebook AI Open Catalyst Project
- *20Microsoft Research Lab - Amsterdam
- 本レポートは当部の取引先配布資料として作成しております。本稿におけるありうる誤りはすべて筆者個人に属します。
- レポートに掲載されているあらゆる内容の無断転載・複製を禁じます。全ての内容は日本の著作権法及び国際条約により保護されています。