
基盤モデルとは —AI開発のパラダイムシフト—
ChatGPTの登場以降、米国のメガテックを中心に基盤モデルの研究開発における競争が激化している。
基盤モデルとは「大量かつ多様なデータで訓練され、多様な用途におけるタスクに適応できるモデル*1」のことである。基盤モデルを活用することで、従来よりも指定したタスクを実行するAIモデルを効率的に構築することが可能である。たとえばChatGPTは「GPT–3.5」や「GPT–4」といった言語に特化した基盤モデル、いわゆる「大規模言語モデル」を使用したサービスであり、基盤モデルの開発は各国における産業競争力や今後のAI開発における覇権争いに直結することが予想される。日本においてもこれらの動きに危機感をもった大手企業や公的研究機関を中心に、今までにないスピード感で研究開発が進められており、政府による研究開発への投資も活発になってきている。
今回は、そうした基盤モデル、特に世界で熾烈な開発競争が展開されている大規模言語モデル開発を中心に論考することで、日本企業が取り組むべき基盤モデル開発の方向性を検討する。
基盤モデルによるAI開発のパラダイムシフト
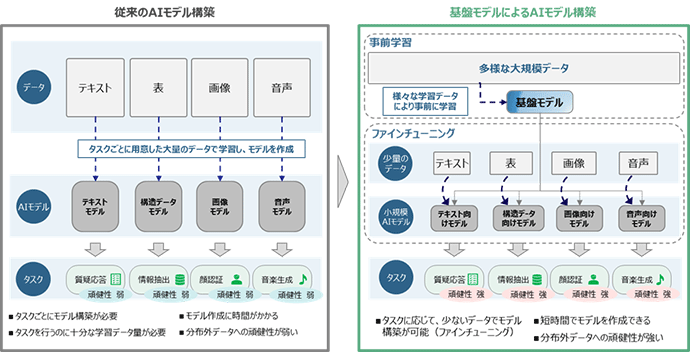
出所:各種資料より、みずほリサーチ&テクノロジーズ作成
拡大図独自の大規模言語モデル開発に取り組む意義
ChatGPTが登場した当初、世界では、その基盤モデルであるGPTシリーズを活用したサービス開発に注力する動きが中心であった。しかし、これらのサービスの普及が進む中で、日本でも大企業を中心として、大規模言語モデルの独自開発に取り組む動きが活発化している。
この動きの背景として、各企業において主に①自社の業務に即したモデルの必要性と、②他社に依存しないモデルの重要性が表出してきたことが挙げられ、海外製基盤モデルではなく、日本独自に開発された使用感の高いモデルを利用したいというニーズが高まっていることが考えられる。
以下では、これら2つの背景について検討を行う。
①自社業務に即したモデルの必要性
GPT等の海外製基盤モデルを構築する際に用いられている学習データは、英語のテキストが中心である。そのため、日本語の細かいニュアンスや状況に応じた意味の違いなどを適切に捉えることが難しい。このことから、日本語のテキストを中心に学習し、日本人の感覚に即した文脈を理解できるモデルが必要である。また、文書作成やコールセンターの自動応答機能など業務効率化に有用なモデルを作成するには、自社内に蓄積されているデータを活用し、モデルの学習を行うほうが効果的である。
自社の業務に特化した基盤モデルの開発例として、Bloombergが開発した金融分野向け大規模言語モデルが挙げられる。金融業界のように専門用語が多い業界では、業界に特化したモデルを開発することで、その領域の業務では高い性能が得られやすく、結果として、GPT–4のようなパラメータ数の多いモデルほどの汎化性能はなくとも、実用性の高いモデルになることが多い。
ほかにも、さまざまな特徴を持つモデルが登場しており、これらの動向も踏まえつつ自社の予算規模や業務目的に応じてモデル開発を行うことは、各企業のAI活用における有効な選択肢になりうると考えられる。
特定の分野に特化した大規模言語モデルの例

出所:各種資料より、みずほリサーチ&テクノロジーズ作成
②他社に依存しないモデルの重要性
他社の大規模言語モデルを活用するデメリットとして、モデル使用における費用や性能の変動リスクが挙げられる。
たとえば、何らかの事情で、基盤モデルを提供する事業者によって、モデルの運用・管理費が引き上げられる。その結果、ユーザー企業が支払うモデルの使用料が上昇し、経営状況に影響を及ぼす可能性がある。また、スタンフォード大学の研究*2では、時間の経過とともにGPT–4の一部性能が低下したと報告されているなど、モデルの出力情報が時間経過とともに変化するリスクもある。
ほかにも、セキュリティ上のリスクとして、入力したプロンプトから自社の機密情報などが外部の企業に流出する可能性があるため、他社モデルの使用においては細心の注意が必要である。
大規模言語モデル開発における課題とその対応
現状の日本企業における研究開発の取り組みから、大規模言語モデル開発においては、モデルの構築に必要となる学習データやノウハウの確保、計算リソースの拡充などが課題として挙げられる。
これらの課題を受けて国は、2023年度当初で1000億円だった政府全体のAI関連予算を2024年度には2000億円規模に倍増することも視野に入れるなど*3、生成AI開発への支援に取り組む姿勢を見せており、関係省庁において具体的な施策が検討・実施されている。
このような動きによって徐々に上記のような課題は解決され、各企業における独自モデルの開発に向けた機運が高まっていくと考えられる。
各省庁の生成AI開発に係る導入支援

出所:各種資料より、みずほリサーチ&テクノロジーズ作成
大規模言語モデル開発における日本企業の勝ち筋とは
前述のように、日本では、日本語や自社に特化した基盤モデルを構築する傾向が強まっていくことが想定される。しかし、大規模言語モデル開発において、日本は後発国であり、モデル開発に関連するノウハウの蓄積やGPUをはじめとする計算資源の確保において海外企業に遅れをとっているのが現状である。また、メガテック企業と比較し、日本企業の基盤モデルの開発に割り当てられる経営資源が相対的に少ないことから、巨額の資金や大量の学習用データ、計算リソースを投じて作られた海外製モデルに、総合的な性能で対抗するのは困難である。
一方で、各企業が大規模言語モデルを使用する際には、海外製のパラメータ数の多い汎用型のモデルを使用しなくとも、各分野の自社業務に即して軽量化された大規模言語モデルで十分である場合が多いと想定される。たとえば、自社に特化したモデルであれば、パラメータ数を抑えることにより、消費電力の抑制や運用費の削減なども可能である。
さらに、独自モデルであれば、データの管理・運用が自社の裁量で実施できるため、セキュリティ面における課題の解消にもつながる。また、仮に自社設備でモデルを稼働することができるのであれば、機微な顧客情報の取り扱いや、外部への接続が困難な環境においての利用も可能になる。以上のことから、自社の業務に特化したモデルの構築は、日本企業にもたらすメリットが大きく、海外企業に対抗する戦略の1つになりうるだろう。
むすび
基盤モデルを活用したAIモデルは、従来よりも幅広い業務の効率化や代替に寄与し、産業競争力向上や人手不足の解消につながると予想されている。
そのような効果を実現する上では、GPT–4のようなすでに活用が進んでいる汎用的・高性能な基盤モデルの活用も有力な選択肢だろう。
一方で、自社の経営戦略や業務の実態に寄り添った活用をするという観点からは、国の支援施策も有効に活用しながら、各企業が自らの保有する資産や経営戦略、業務の実態を踏まえた最適な独自モデルを追求していくことが重要になるだろう。
そのために、まずは早急に具体的なユースケースや他社動向などの情報収集を進め、それらの情報を踏まえながら、自社におけるAIの活用場面をイメージすることが必要である。
-
*1Stanford University Human–Centered Artificial Intelligence, Machine Learning Reflections on Foundation Models
-
*2Lingjiao et al.,「How Is Chat GPT's Behavior Changing over Time?」, arXiv
-
*324年度AI予算、開発インフラに重点 倍の2000億円視野(日本経済新聞、2023年8月2日)
(CONTACT)

お問い合わせ
お問い合わせは個人情報のお取扱いについてをご参照いただき、同意のうえ、以下のメールアドレスまでご連絡ください。
サービスに関するお問い合わせはこちら
メール内にご希望のサービス名の記載をお願いします。
mhricon-service-info@mizuho-rt.co.jp
その他のお問い合わせはこちら
mhricon-info@mizuho-rt.co.jp






