合成生物学に基づくバイオものづくりについて(1/2)
2024年9月
みずほリサーチ&テクノロジーズ サイエンスソリューション部 三澤 文香
- *本稿は、2024年3月に「みずほリサーチ&テクノロジーズ技報 Vol.3 No.1」で発表した内容となります。
はじめに
2009年にOECDで「バイオエコノミー」の概念が提唱され、バイオテクノロジーが、経済生産や人口増加、食料問題、気候変動といった課題解決及び持続可能な社会を実現させる方法の一つとして注目されるようになった。中でも近年注目されているのが合成生物学である。各国は合成生物学を基盤とした物質生産である「バイオものづくり」を社会実装し、化石資源を利用する化学プロセスからバイオプロセスへの転換、化学プロセスでは合成ができない物質生産の実現を目指している。米国や中国を中心に合成生物学への積極的な投資がなされ、日本でも合成生物学を重要分野と位置付け研究開発投資をしている。本レポートでは、合成生物学の概要と研究開発の鍵となるプロセスであるDBTLサイクルの技術動向について整理し、社会実装に向けた動きを紹介する。
合成生物学の概要 台頭の背景
合成生物学は、「組織、細胞、遺伝子といった生物の要素を部品とみなし、それらを組み合わせて生命機能を人工的に設計したり、人工の生物システムを構築したりする学問分野」であり、多少の誤解を恐れずに言うと、「新たな生物機能、生命の創出を試みる学問分野」といえる。合成生物学の台頭の背景には、生物学の知見の蓄積に加え、近年のバイオテクノロジーやデジタル技術の革新の寄与が大きいとされる。特に以下の3点のインパクトは大きい。
(1)ゲノム編集技術、DNA合成技術の技術向上
ゲノム編集技術は酵素を利用しゲノムを構成するDNAを切断し、遺伝子を書き換える技術である。これにより自由にDNA配列をデザインし、狙った生物機能の実現が可能となった。中でも、2020年にノーベル化学賞を受賞したCRISPR/Cas9と呼ばれるゲノム編集技術の開発により、低コスト且つ、簡便な実験による改変が可能となった。また、DNAの構成単位である塩基を化学的に繋げてDNA配列を創り出す技術であるDNA合成技術の向上により、デザインした配列の合成が容易となったインパクトも大きい。
(2)次世代シークエンサーの登場
シークエンサーは塩基配列情報を読み取る装置である。2000年代に大量の配列決定が可能な次世代シークエンサーが登場、普及したことにより、ゲノム解析の高速化・低コスト化が実現した。これによりゲノム情報の解析、収集が大幅に進んだ。
(3)IoT・AI技術の発展
機械学習やディープラーニングの適用がなされ、ゲノム配列をはじめとする生物情報と生物機能の関係の解明が進んだ。また複雑な代謝経路等の設計が可能となった。ロボティクスの観点では、実験の自動化・高速化が実現し研究開発期間の短縮が可能となった。
従来の生物学研究では、研究者個人の手作業が中心の経験則に基づくアプローチが中心であり、研究活動の質、量ともに限定された範囲に留まっていた。しかし技術革新により自動化やデータ駆動型のアプローチが可能となり、迅速かつ網羅的な検証を行うアプローチへの転換が可能になった。これら技術革新は合成生物学のプロセスでも重要な役割を果たしている。
合成生物学のプロセス
合成生物学では、人工的に生命機能の設計、生物システムの構築を試みる。その際には目的に適した設計図(遺伝子や代謝経路)を作り、実際に構築(DNAを合成、ゲノム編集)し、微生物・細胞に取り込み、機能を評価し設計にフィードバックするといったサイクルを回すことが重要となる。このサイクルは、設計(Design)、構築(Build)、評価(Test)、学習(Learn)の4つのプロセスから構成され、各プロセスの頭文字をとりDBTLサイクルと呼ばれている。このDBTLサイクルは、ものづくり、特にソフトウェア開発における反復型開発と類似している。
図1 DBTLサイクル
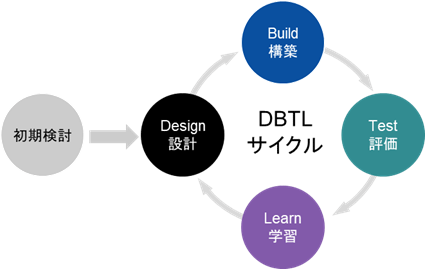
- (出所)各種資料を参考にみずほリサーチ&テクノロジーズ作成
合成生物学ではDBTLサイクルを繰り返し最適な微生物・細胞を創出することが重要となる。以降に各工程の概要と利用される技術、国内の研究事例について整理する。なお、研究事例は新エネルギー・産業技術総合開発機構(NEDO)「植物等の生物を用いた高機能品生産技術の開発(スマートセルプロジェクト)*1」の成果を中心に整理した。
(1)初期検討
期検討は生産物質を検討する工程である。現状、生産物質ありきでDBTLサイクルの検討が進められることが多いが、合成生物学で合成でき、許容できるコストで生産できる物質を見つけることは、DBTLサイクルの検討に留まらず、社会実装を検討する場面等でも重要になると考える。
この工程では、生命現象をコンピュータを使って研究する分野であるバイオインフォマティクスに加え、機能性の物質をデザインするマテリアルズインフォマティクスや化学における情報科学分野であるケモインフォマティクスを組み合わせて検討する必要がある。
(2)設計(Design)
設計(Design)は、初期検討で決めた物質を生産するための代謝経路や遺伝子配列を設計する工程である。具体的には、①目的の物質の生産に適した微生物・細胞の選抜、②代謝経路を選択または新規設計、③選択した経路に適した酵素や導入遺伝子を選択、④遺伝子配列及び実験の設計、の流れとなる。
この工程では、バイオデータベースやバイオインフォマティクスを中心とした情報解析技術を用いて、最適な経路や配列の設計が重要となる。バイオデータベースには、塩基、アミノ酸、タンパク質機能等の情報別のデータベースや統合的に整理されたデータベース等、様々な形態がみられる。国内の統合的なデータベースの一例として、NITEバイオテクノロジーセンター(NBRC)の「生物資源データプラットフォーム(DBRP)*2」が挙げられる。DBRPは、NBRCが保有する5万株以上の微生物に関わる生物資源情報に加え、各微生物の物質生産や薬剤耐性の情報、文献情報、オミックス情報、国家プロジェクトにより得られた実験情報等の様々な情報が整理されている。
バイオインフォマティクスとしては代謝経路設計、酵素選択、酵素改変設計(分子動力学シミュレーション)、遺伝子配列設計技術(コドン最適化・プロモーター改変)等が挙げられる。現状様々なアプローチで情報解析技術の研究がなされているが、代謝経路や遺伝子配列の分析予測の高度化に加え、汎用性の確保や最適なツールの選定も重要になると考える。
(3)構築(Build)
構築(Build)は、設計した微生物・細胞を物理的に構築する工程である。アプローチは複数あるがDNA合成装置を用いて構築を試みる場合は、①DNA合成・アセンブリ、②合成したDNA等の精製、③配列評価、④微生物・細胞への導入、の流れとなる。
この工程では、DNA合成技術やゲノム編集、配列解析等の技術が用いられる。DNA合成においては、長鎖DNA合成の期間短縮、低コスト化、精度の向上に資する研究開発がなされている。代表的な国内の事例としては、枯草菌を用いた50個以上のDNA断片を連結可能な遺伝子集積技術であるOGAB法を用いた長鎖DNA合成技術が挙げられ、30kb程度の長鎖DNAを1塩基当たり数円、2週間程度の短期間で合成可能となったと報告がされている*3。従来は合成難易度が高い配列を含む長鎖DNA合成には2カ月以上の期間を要していたことから大幅な期間短縮である*4。現在は神戸大学発のベンチャーであるシンプロジェンにおいてOGAB法を応用したDNA合成サービスが展開されている*4,5。
ゲノム編集技術としてはCRISPR/Cas9が有名であるが、オフターゲット変異や標的配列の制限といった技術的課題や知的財産の課題があるため国内でCRISPR/CAS系やTALENを改良・応用した技術開発が進められている。具体的には、1塩基のみを別の塩基に変換するゲノム編集技術(Target-AID)*6や、配列を認識する特異性を高め広範囲な様式の変異を導入できるゲノム編集技術(TiD)*7、PPRタンパク質を利用し任意のDNA・RNAに結合させるゲノム編集技術*8等が挙げられる。
(4)評価(Test)
評価(Test)は、構築した微生物・細胞をプロトタイプ化し、目的物質の産生試験を実施する工程である。具体的には①微生物・細胞の増殖、②生産物の抽出、③データの取得、④データ解析・評価、の流れとなる。評価では、生産物質の検出と定量に加え、次のDBTLサイクルへのフィードバックのための情報取得も兼ねるため、DNA、mRNA、タンパク質、代謝物の情報(種類、量、生体内分布等)を網羅的に取得し、オミックス解析を行う必要がある。
この工程では、生物情報の取得と解析が重要となる。生物情報の取得には様々な装置を用いるが、その一例として国内では液体クロマトグラフ質量分析計(LC-MS/MS)に係る研究が進められている。例えば、神戸大学では、メタボローム解析システムの開発として、150種類の代謝物の一斉分析や分析の高感度化、前処理工程の自動化やデータ解析システムの構築といった作業・開発時間の短縮に資する開発*9が行われ、大阪大学では、高精度定量ターゲットプロテオミクス法に注目した数十種のタンパク質の発現量の分析の高感度化、一斉定量の手法の開発*10がなされている。
また取得された生物情報は、メタボローム解析、プロテオーム解析、メタボローム解析等のオミックス解析において分析評価される。情報解析技術の適用効果は、解析する情報の質・量にも依存する。そのため、前述した生物情報の取得に係る研究が進むことで情報解析技術の適用効果もより高まることが想定される。
(5)学習(Learn)
学習(Learn)は、機械学習を用いて産生物質を評価・解析しプロセスを最適化する工程である。評価(Test)で取得した情報を用いてボトルネックの分析、生産の効率化、データベースの充実化を実施し、次のDBTLサイクルへと適用していくフェーズである。
この工程では、発現ネットワーク構築技術、配列・構造検出技術、有望遺伝子レコメンド技術、輸送体探索技術等のバイオインフォマティクスや機械学習が用いられる。これまでは、実験データやデータベースに拡散した情報、文献・特許情報をマニュアルで調査し、研究者の直観による意思決定がされていたが、大量の生物情報を用いた解析、更には機械学習等の適用を試みることでより効率的かつ信頼性を上げることが可能となりつつある。
DBTLサイクルに係る研究開発は進み実際にサイクルを利用したスマートセルの創出がなされている*11。今後は、より高機能な微生物・細胞を開発するためにDBTLサイクルの更なる高度化等に資する技術開発が中心となることが想定される。具体的には、「量、質共に十分な生物情報の取得」「取得した生物情報の解析方法やデータベース整備」「実験を含めたプロセスの効率化、自動化」が想定され、バイオテクノロジーのみならず、AI等のデジタル技術の適用、ロボティクスや自動化の適用が鍵となるだろう。
- 本レポートは当部の取引先配布資料として作成しております。本稿におけるありうる誤りはすべて筆者個人に属します。
- レポートに掲載されているあらゆる内容の無断転載・複製を禁じます。全ての内容は日本の著作権法及び国際条約により保護されています。
関連情報
この執筆者はこちらも執筆しています
- 2023年7月
- 建設分野における価格動向について
- 2022年3月10日
- ドローンによるプラント点検の動向